设计模式学习笔记[02]
本笔记内容源于王争的《设计模式之美》课程。
四、设计模式与范式:创建型
单例模式
what
单例设计模式(Singleton Design Pattern)理解起来非常简单。一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
why
实战案例一:处理资源访问冲突
先来看第一个例子。在这个例子中,我们自定义实现了一个往文件中打印日志的Logger类。具体的代码实现如下所示:
public class Logger {
private FileWriter writer;
public Logger() {
File file = new File("/Users/wangzheng/log.txt");
writer = new FileWriter(file, true); //true表示追加写入
}
public void log(String message) {
writer.write(mesasge);
}
}
// Logger类的应用示例:
public class UserController {
private Logger logger = new Logger();
public void login(String username, String password) {
// ...省略业务逻辑代码...
logger.log(username + " logined!");
}
}
public class OrderController {
private Logger logger = new Logger();
public void create(OrderVo order) {
// ...省略业务逻辑代码...
logger.log("Created an order: " + order.toString());
}
}
在上面的代码中,我们注意到,所有的日志都写入到同一个文件/Users/wangzheng/log.txt中。在UserController和OrderController中,我们分别创建两个Logger对象。在Web容器的Servlet多线程环境下,如果两个Servlet线程同时分别执行login()和create()两个函数,并且同时写日志到log.txt文件中,那就有可能存在日志信息互相覆盖的情况。
那如何来解决这个问题呢?我们最先想到的就是通过加锁的方式:给log()函数加互斥锁(Java中可以通过synchronized的关键字),同一时刻只允许一个线程调用执行log()函数。具体的代码实现如下所示:
public class Logger {
private FileWriter writer;
public Logger() {
File file = new File("/Users/wangzheng/log.txt");
writer = new FileWriter(file, true); //true表示追加写入
}
public void log(String message) {
synchronized(this) {
writer.write(mesasge);
}
}
}
仔细想想,这真的能解决多线程写入日志时互相覆盖的问题吗?答案是否定的。这是因为,这种锁是一个对象级别的锁,一个对象在不同的线程下同时调用log()函数,会被强制要求顺序执行。但是,不同的对象之间并不共享同一把锁。在不同的线程下,通过不同的对象调用执行log()函数,锁并不会起作用,仍然有可能存在写入日志互相覆盖的问题。不过,我们给log()函数加不加对象级别的锁,其实都没有关系。因为FileWriter本身就是线程安全的,它的内部实现中本身就加了对象级别的锁,因此,在外层调用write()函数的时候,再加对象级别的锁实际上是多此一举。因为不同的Logger对象不共享FileWriter对象,所以,FileWriter对象级别的锁也解决不了数据写入互相覆盖的问题。
那我们该怎么解决这个问题呢?实际上,要想解决这个问题也不难,我们只需要把对象级别的锁,换成类级别的锁就可以了。让所有的对象都共享同一把锁。这样就避免了不同对象之间同时调用log()函数,而导致的日志覆盖问题。具体的代码实现如下所示:
public class Logger {
private FileWriter writer;
public Logger() {
File file = new File("/Users/wangzheng/log.txt");
writer = new FileWriter(file, true); //true表示追加写入
}
public void log(String message) {
synchronized(Logger.class) { // 类级别的锁
writer.write(mesasge);
}
}
}
除了使用类级别锁之外,实际上,解决资源竞争问题的办法还有很多,分布式锁是最常听到的一种解决方案。不过,实现一个安全可靠、无bug、高性能的分布式锁,并不是件容易的事情。除此之外,并发队列(比如Java中的BlockingQueue)也可以解决这个问题:多个线程同时往并发队列里写日志,一个单独的线程负责将并发队列中的数据,写入到日志文件。这种方式实现起来也稍微有点复杂。
相对于这两种解决方案,单例模式的解决思路就简单一些了。单例模式相对于之前类级别锁的好处是,不用创建那么多Logger对象,一方面节省内存空间,另一方面节省系统文件句柄(对于操作系统来说,文件句柄也是一种资源,不能随便浪费)。
我们将Logger设计成一个单例类,程序中只允许创建一个Logger对象,所有的线程共享使用的这一个Logger对象,共享一个FileWriter对象,而FileWriter本身是对象级别线程安全的,也就避免了多线程情况下写日志会互相覆盖的问题。
按照这个设计思路,我们实现了Logger单例类。具体代码如下所示:
public class Logger {
private FileWriter writer;
private static final Logger instance = new Logger();
private Logger() {
File file = new File("/Users/wangzheng/log.txt");
writer = new FileWriter(file, true); //true表示追加写入
}
public static Logger getInstance() {
return instance;
}
public void log(String message) {
writer.write(mesasge);
}
}
// Logger类的应用示例:
public class UserController {
public void login(String username, String password) {
// ...省略业务逻辑代码...
Logger.getInstance().log(username + " logined!");
}
}
public class OrderController {
public void create(OrderVo order) {
// ...省略业务逻辑代码...
Logger.getInstance().log("Created a order: " + order.toString());
}
}
实战案例二:表示全局唯一类
从业务概念上,如果有些数据在系统中只应保存一份,那就比较适合设计为单例类。
比如,配置信息类。在系统中,我们只有一个配置文件,当配置文件被加载到内存之后,以对象的形式存在,也理所应当只有一份。
再比如,唯一递增ID号码生成器(第34讲中我们讲的是唯一ID生成器,这里讲的是唯一递增ID生成器),如果程序中有两个对象,那就会存在生成重复ID的情况,所以,我们应该将ID生成器类设计为单例。
how
尽管介绍如何实现一个单例模式的文章已经有很多了,但为了保证内容的完整性,我这里还是简单介绍一下几种经典实现方式。概括起来,要实现一个单例,我们需要关注的点无外乎下面几个:
- 构造函数需要是private访问权限的,这样才能避免外部通过new创建实例;
- 考虑对象创建时的线程安全问题;
- 考虑是否支持延迟加载;
- 考虑getInstance()性能是否高(是否加锁)。
饿汉式
饿汉式的实现方式比较简单。在类加载的时候,instance静态实例就已经创建并初始化好了,所以,instance实例的创建过程是线程安全的。不过,这样的实现方式不支持延迟加载。
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static final IdGenerator instance = new IdGenerator();
private IdGenerator() {}
public static IdGenerator getInstance() {
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
有人觉得这种实现方式不好,因为不支持延迟加载,如果实例占用资源多(比如占用内存多)或初始化耗时长(比如需要加载各种配置文件),提前初始化实例是一种浪费资源的行为。最好的方法应该在用到的时候再去初始化。不过,我个人并不认同这样的观点。
如果初始化耗时长,那我们最好不要等到真正要用它的时候,才去执行这个耗时长的初始化过程,这会影响到系统的性能(比如,在响应客户端接口请求的时候,做这个初始化操作,会导致此请求的响应时间变长,甚至超时)。采用饿汉式实现方式,将耗时的初始化操作,提前到程序启动的时候完成,这样就能避免在程序运行的时候,再去初始化导致的性能问题。
如果实例占用资源多,按照fail-fast的设计原则(有问题及早暴露),那我们也希望在程序启动时就将这个实例初始化好。如果资源不够,就会在程序启动的时候触发报错(比如Java中的 PermGen Space OOM),我们可以立即去修复。这样也能避免在程序运行一段时间后,突然因为初始化这个实例占用资源过多,导致系统崩溃,影响系统的可用性。
懒汉式
懒汉式相对于饿汉式的优势是支持延迟加载。
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static IdGenerator instance;
private IdGenerator() {}
public static synchronized IdGenerator getInstance() {
if (instance == null) {
instance = new IdGenerator();
}
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
不过懒汉式的缺点也很明显,我们给getInstance()这个方法加了一把大锁(synchronzed),导致这个函数的并发度很低。量化一下的话,并发度是1,也就相当于串行操作了。而这个函数是在单例使用期间,一直会被调用。如果这个单例类偶尔会被用到,那这种实现方式还可以接受。但是,如果频繁地用到,那频繁加锁、释放锁及并发度低等问题,会导致性能瓶颈,这种实现方式就不可取了。
双重检测
饿汉式不支持延迟加载,懒汉式有性能问题,不支持高并发。那我们再来看一种既支持延迟加载、又支持高并发的单例实现方式,也就是双重检测实现方式。
在这种实现方式中,只要instance被创建之后,即便再调用getInstance()函数也不会再进入到加锁逻辑中了。所以,这种实现方式解决了懒汉式并发度低的问题。具体的代码实现如下所示:
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static IdGenerator instance;
private IdGenerator() {}
public static IdGenerator getInstance() {
if (instance == null) {
synchronized(IdGenerator.class) { // 此处为类级别的锁
if (instance == null) {
instance = new IdGenerator();
}
}
}
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
有人说,这种实现方式有些问题。因为指令重排序,可能会导致IdGenerator对象被new出来,并且赋值给instance之后,还没来得及初始化(执行构造函数中的代码逻辑),就被另一个线程使用了。
要解决这个问题,我们需要给instance成员变量加上volatile关键字,禁止指令重排序才行。实际上,只有很低版本的Java才会有这个问题。我们现在用的高版本的Java已经在JDK内部实现中解决了这个问题(解决的方法很简单,只要把对象new操作和初始化操作设计为原子操作,就自然能禁止重排序)。
静态内部类
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private IdGenerator() {}
private static class SingletonHolder{
private static final IdGenerator instance = new IdGenerator();
}
public static IdGenerator getInstance() {
return SingletonHolder.instance;
}
public long getId() {
return id.incrementAndGet();
}
}
SingletonHolder 是一个静态内部类,当外部类IdGenerator被加载的时候,并不会创建SingletonHolder实例对象。只有当调用getInstance()方法时,SingletonHolder才会被加载,这个时候才会创建instance。instance的唯一性、创建过程的线程安全性,都由JVM来保证。所以,这种实现方法既保证了线程安全,又能做到延迟加载。
枚举
最简单的实现方式,基于枚举类型的单例实现。这种实现方式通过Java枚举类型本身的特性,保证了实例创建的线程安全性和实例的唯一性。
public enum IdGenerator {
INSTANCE;
private AtomicLong id = new AtomicLong(0);
public long getId() {
return id.incrementAndGet();
}
}
存在的问题
大部分情况下,我们在项目中使用单例,都是用它来表示一些全局唯一类,比如配置信息类、连接池类、ID生成器类。单例模式书写简洁、使用方便,在代码中,我们不需要创建对象,直接通过类似IdGenerator.getInstance().getId()这样的方法来调用就可以了。但是,这种使用方法有点类似硬编码(hard code),会带来诸多问题。
1.单例对OOP特性的支持不友好
我们知道,OOP的四大特性是封装、抽象、继承、多态。单例这种设计模式对于其中的抽象、继承、多态都支持得不好。
public class Order {
public void create(...) {
//...
long id = IdGenerator.getInstance().getId();
//...
}
}
public class User {
public void create(...) {
// ...
long id = IdGenerator.getInstance().getId();
//...
}
}
IdGenerator的使用方式违背了基于接口而非实现的设计原则,也就违背了广义上理解的OOP的抽象特性。如果未来某一天,我们希望针对不同的业务采用不同的ID生成算法。比如,订单ID和用户ID采用不同的ID生成器来生成。为了应对这个需求变化,我们需要修改所有用到IdGenerator类的地方,这样代码的改动就会比较大。
public class Order {
public void create(...) {
//...
long id = IdGenerator.getInstance().getId();
// 需要将上面一行代码,替换为下面一行代码
long id = OrderIdGenerator.getIntance().getId();
//...
}
}
public class User {
public void create(...) {
// ...
long id = IdGenerator.getInstance().getId();
// 需要将上面一行代码,替换为下面一行代码
long id = UserIdGenerator.getIntance().getId();
}
}
除此之外,单例对继承、多态特性的支持也不友好。这里我之所以会用“不友好”这个词,而非“完全不支持”,是因为从理论上来讲,单例类也可以被继承、也可以实现多态,只是实现起来会非常奇怪,会导致代码的可读性变差。不明白设计意图的人,看到这样的设计,会觉得莫名其妙。所以,一旦你选择将某个类设计成到单例类,也就意味着放弃了继承和多态这两个强有力的面向对象特性,也就相当于损失了可以应对未来需求变化的扩展性。
2.单例会隐藏类之间的依赖关系
我们知道,代码的可读性非常重要。在阅读代码的时候,我们希望一眼就能看出类与类之间的依赖关系,搞清楚这个类依赖了哪些外部类。
通过构造函数、参数传递等方式声明的类之间的依赖关系,我们通过查看函数的定义,就能很容易识别出来。但是,单例类不需要显示创建、不需要依赖参数传递,在函数中直接调用就可以了。如果代码比较复杂,这种调用关系就会非常隐蔽。在阅读代码的时候,我们就需要仔细查看每个函数的代码实现,才能知道这个类到底依赖了哪些单例类。
3.单例对代码的扩展性不友好
我们知道,单例类只能有一个对象实例。如果未来某一天,我们需要在代码中创建两个实例或多个实例,那就要对代码有比较大的改动。你可能会说,会有这样的需求吗?既然单例类大部分情况下都用来表示全局类,怎么会需要两个或者多个实例呢?
实际上,这样的需求并不少见。我们拿数据库连接池来举例解释一下。
在系统设计初期,我们觉得系统中只应该有一个数据库连接池,这样能方便我们控制对数据库连接资源的消耗。所以,我们把数据库连接池类设计成了单例类。但之后我们发现,系统中有些SQL语句运行得非常慢。这些SQL语句在执行的时候,长时间占用数据库连接资源,导致其他SQL请求无法响应。为了解决这个问题,我们希望将慢SQL与其他SQL隔离开来执行。为了实现这样的目的,我们可以在系统中创建两个数据库连接池,慢SQL独享一个数据库连接池,其他SQL独享另外一个数据库连接池,这样就能避免慢SQL影响到其他SQL的执行。
如果我们将数据库连接池设计成单例类,显然就无法适应这样的需求变更,也就是说,单例类在某些情况下会影响代码的扩展性、灵活性。所以,数据库连接池、线程池这类的资源池,最好还是不要设计成单例类。实际上,一些开源的数据库连接池、线程池也确实没有设计成单例类。
4.单例对代码的可测试性不友好
单例模式的使用会影响到代码的可测试性。如果单例类依赖比较重的外部资源,比如DB,我们在写单元测试的时候,希望能通过mock的方式将它替换掉。而单例类这种硬编码式的使用方式,导致无法实现mock替换。
除此之外,如果单例类持有成员变量(比如IdGenerator中的id成员变量),那它实际上相当于一种全局变量,被所有的代码共享。如果这个全局变量是一个可变全局变量,也就是说,它的成员变量是可以被修改的,那我们在编写单元测试的时候,还需要注意不同测试用例之间,修改了单例类中的同一个成员变量的值,从而导致测试结果互相影响的问题。
5.单例不支持有参数的构造函数
单例不支持有参数的构造函数,比如我们创建一个连接池的单例对象,我们没法通过参数来指定连接池的大小。针对这个问题,我们来看下都有哪些解决方案。
第一种解决思路是:创建完实例之后,再调用init()函数传递参数。需要注意的是,我们在使用这个单例类的时候,要先调用init()方法,然后才能调用getInstance()方法,否则代码会抛出异常。具体的代码实现如下所示:
public class Singleton {
private static Singleton instance = null;
private final int paramA;
private final int paramB;
private Singleton(int paramA, int paramB) {
this.paramA = paramA;
this.paramB = paramB;
}
public static Singleton getInstance() {
if (instance == null) {
throw new RuntimeException("Run init() first.");
}
return instance;
}
public synchronized static Singleton init(int paramA, int paramB) {
if (instance != null){
throw new RuntimeException("Singleton has been created!");
}
instance = new Singleton(paramA, paramB);
return instance;
}
}
Singleton.init(10, 50); // 先init,再使用
Singleton singleton = Singleton.getInstance();
第二种解决思路是:将参数放到getIntance()方法中。具体的代码实现如下所示:
public class Singleton {
private static Singleton instance = null;
private final int paramA;
private final int paramB;
private Singleton(int paramA, int paramB) {
this.paramA = paramA;
this.paramB = paramB;
}
public synchronized static Singleton getInstance(int paramA, int paramB) {
if (instance == null) {
instance = new Singleton(paramA, paramB);
}
return instance;
}
}
Singleton singleton = Singleton.getInstance(10, 50);
第三种解决思路是:将参数放到另外一个全局变量中。具体的代码实现如下。Config是一个存储了paramA和paramB值的全局变量。里面的值既可以像下面的代码那样通过静态常量来定义,也可以从配置文件中加载得到。实际上,这种方式是最值得推荐的。
public class Config {
public static final int PARAM_A = 123;
public static final int PARAM_B = 245;
}
public class Singleton {
private static Singleton instance = null;
private final int paramA;
private final int paramB;
private Singleton() {
this.paramA = Config.PARAM_A;
this.paramB = Config.PARAM_B;
}
public synchronized static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
替代解决方案
刚刚我们提到了单例的很多问题,你可能会说,即便单例有这么多问题,但我不用不行啊。我业务上有表示全局唯一类的需求,如果不用单例,我怎么才能保证这个类的对象全局唯一呢?
为了保证全局唯一,除了使用单例,我们还可以用静态方法来实现。这也是项目开发中经常用到的一种实现思路。比如,上一节课中讲的ID唯一递增生成器的例子,用静态方法实现一下,就是下面这个样子:
// 静态方法实现方式
public class IdGenerator {
private static AtomicLong id = new AtomicLong(0);
public static long getId() {
return id.incrementAndGet();
}
}
// 使用举例
long id = IdGenerator.getId();
不过,静态方法这种实现思路,并不能解决我们之前提到的问题。实际上,它比单例更加不灵活,比如,它无法支持延迟加载。我们再来看看有没有其他办法。实际上,单例除了我们之前讲到的使用方法之外,还有另外一种使用方法。具体的代码如下所示:
// 1. 老的使用方式
public demofunction() {
//...
long id = IdGenerator.getInstance().getId();
//...
}
// 2. 新的使用方式:依赖注入
public demofunction(IdGenerator idGenerator) {
long id = idGenerator.getId();
}
// 外部调用demofunction()的时候,传入idGenerator
IdGenerator idGenerator = IdGenerator.getInsance();
demofunction(idGenerator);
基于新的使用方式,我们将单例生成的对象,作为参数传递给函数(也可以通过构造函数传递给类的成员变量),可以解决单例隐藏类之间依赖关系的问题。不过,对于单例存在的其他问题,比如对OOP特性、扩展性、可测性不友好等问题,还是无法解决。
所以,如果要完全解决这些问题,我们可能要从根上,寻找其他方式来实现全局唯一类。实际上,类对象的全局唯一性可以通过多种不同的方式来保证。我们既可以通过单例模式来强制保证,也可以通过工厂模式、IOC容器(比如Spring IOC容器)来保证,还可以通过程序员自己来保证(自己在编写代码的时候自己保证不要创建两个类对象)。
如何理解单例模式中的唯一性?
“一个类只允许创建唯一一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。”定义中提到,“一个类只允许创建唯一一个对象”。那对象的唯一性的作用范围是什么呢?是指线程内只允许创建一个对象,还是指进程内只允许创建一个对象?答案是后者,也就是说,单例模式创建的对象是进程唯一的。
如何实现线程唯一的单例?
“进程唯一”指的是进程内唯一,进程间不唯一。类比一下,“线程唯一”指的是线程内唯一,线程间可以不唯一。实际上,“进程唯一”还代表了线程内、线程间都唯一,这也是“进程唯一”和“线程唯一”的区别之处。
线程唯一单例的代码实现很简单,如下所示。在代码中,我们通过一个HashMap来存储对象,其中key是线程ID,value是对象。这样我们就可以做到,不同的线程对应不同的对象,同一个线程只能对应一个对象。实际上,Java语言本身提供了ThreadLocal工具类,可以更加轻松地实现线程唯一单例。不过,ThreadLocal底层实现原理也是基于下面代码中所示的HashMap。
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static final ConcurrentHashMap<Long, IdGenerator> instances
= new ConcurrentHashMap<>();
private IdGenerator() {}
public static IdGenerator getInstance() {
Long currentThreadId = Thread.currentThread().getId();
instances.putIfAbsent(currentThreadId, new IdGenerator());
return instances.get(currentThreadId);
}
public long getId() {
return id.incrementAndGet();
}
}
如何实现集群环境下的单例?
将“集群唯一”跟“进程唯一”“线程唯一”做个对比。“进程唯一”指的是进程内唯一、进程间不唯一。“线程唯一”指的是线程内唯一、线程间不唯一。集群相当于多个进程构成的一个集合,“集群唯一”就相当于是进程内唯一、进程间也唯一。也就是说,不同的进程间共享同一个对象,不能创建同一个类的多个对象。
我们知道,经典的单例模式是进程内唯一的,那如何实现一个进程间也唯一的单例呢?如果严格按照不同的进程间共享同一个对象来实现,那集群唯一的单例实现起来就有点难度了。
具体来说,我们需要把这个单例对象序列化并存储到外部共享存储区(比如文件)。进程在使用这个单例对象的时候,需要先从外部共享存储区中将它读取到内存,并反序列化成对象,然后再使用,使用完成之后还需要再存储回外部共享存储区。
为了保证任何时刻,在进程间都只有一份对象存在,一个进程在获取到对象之后,需要对对象加锁,避免其他进程再将其获取。在进程使用完这个对象之后,还需要显式地将对象从内存中删除,并且释放对对象的加锁。
按照这个思路,我用伪代码实现了一下这个过程,具体如下所示:
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static IdGenerator instance;
private static SharedObjectStorage storage = FileSharedObjectStorage(/*入参省略,比如文件地址*/);
private static DistributedLock lock = new DistributedLock();
private IdGenerator() {}
public synchronized static IdGenerator getInstance()
if (instance == null) {
lock.lock();
instance = storage.load(IdGenerator.class);
}
return instance;
}
public synchroinzed void freeInstance() {
storage.save(this, IdGeneator.class);
instance = null; //释放对象
lock.unlock();
}
public long getId() {
return id.incrementAndGet();
}
}
// IdGenerator使用举例
IdGenerator idGeneator = IdGenerator.getInstance();
long id = idGenerator.getId();
IdGenerator.freeInstance();
如何实现一个多例模式?
“单例”指的是,一个类只能创建一个对象。对应地,“多例”指的就是,一个类可以创建多个对象,但是个数是有限制的,比如只能创建3个对象。如果用代码来简单示例一下的话,就是下面这个样子:
public class BackendServer {
private long serverNo;
private String serverAddress;
private static final int SERVER_COUNT = 3;
private static final Map<Long, BackendServer> serverInstances = new HashMap<>();
static {
serverInstances.put(1L, new BackendServer(1L, "192.134.22.138:8080"));
serverInstances.put(2L, new BackendServer(2L, "192.134.22.139:8080"));
serverInstances.put(3L, new BackendServer(3L, "192.134.22.140:8080"));
}
private BackendServer(long serverNo, String serverAddress) {
this.serverNo = serverNo;
this.serverAddress = serverAddress;
}
public BackendServer getInstance(long serverNo) {
return serverInstances.get(serverNo);
}
public BackendServer getRandomInstance() {
Random r = new Random();
int no = r.nextInt(SERVER_COUNT)+1;
return serverInstances.get(no);
}
}
实际上,对于多例模式,还有一种理解方式:同一类型的只能创建一个对象,不同类型的可以创建多个对象。这里的“类型”如何理解呢?
我们还是通过一个例子来解释一下,具体代码如下所示。在代码中,logger name就是刚刚说的“类型”,同一个logger name获取到的对象实例是相同的,不同的logger name获取到的对象实例是不同的。
public class Logger {
private static final ConcurrentHashMap<String, Logger> instances
= new ConcurrentHashMap<>();
private Logger() {}
public static Logger getInstance(String loggerName) {
instances.putIfAbsent(loggerName, new Logger());
return instances.get(loggerName);
}
public void log() {
//...
}
}
//l1==l2, l1!=l3
Logger l1 = Logger.getInstance("User.class");
Logger l2 = Logger.getInstance("User.class");
Logger l3 = Logger.getInstance("Order.class");
这种多例模式的理解方式有点类似工厂模式。它跟工厂模式的不同之处是,多例模式创建的对象都是同一个类的对象,而工厂模式创建的是不同子类的对象,关于这一点,下一节课中就会讲到。实际上,它还有点类似享元模式,两者的区别等到我们讲到享元模式的时候再来分析。除此之外,实际上,枚举类型也相当于多例模式,一个类型只能对应一个对象,一个类可以创建多个对象。
工厂模式
what
一般情况下,工厂模式(Factory Design Pattern)分为三种更加细分的类型:简单工厂、工厂方法和抽象工厂。不过,在GoF的《设计模式》一书中,它将简单工厂模式看作是工厂方法模式的一种特例,所以工厂模式只被分成了工厂方法和抽象工厂两类。实际上,前面一种分类方法更加常见。
how
简单工厂(Simple Factory)
在下面这段代码中,我们根据配置文件的后缀(json、xml、yaml、properties),选择不同的解析器(JsonRuleConfigParser、XmlRuleConfigParser……),将存储在文件中的配置解析成内存对象RuleConfig。
public class RuleConfigSource {
public RuleConfig load(String ruleConfigFilePath) {
String ruleConfigFileExtension = getFileExtension(ruleConfigFilePath);
IRuleConfigParser parser = null;
if ("json".equalsIgnoreCase(ruleConfigFileExtension)) {
parser = new JsonRuleConfigParser();
} else if ("xml".equalsIgnoreCase(ruleConfigFileExtension)) {
parser = new XmlRuleConfigParser();
} else if ("yaml".equalsIgnoreCase(ruleConfigFileExtension)) {
parser = new YamlRuleConfigParser();
} else if ("properties".equalsIgnoreCase(ruleConfigFileExtension)) {
parser = new PropertiesRuleConfigParser();
} else {
throw new InvalidRuleConfigException(
"Rule config file format is not supported: " + ruleConfigFilePath);
}
String configText = "";
//从ruleConfigFilePath文件中读取配置文本到configText中
RuleConfig ruleConfig = parser.parse(configText);
return ruleConfig;
}
private String getFileExtension(String filePath) {
//...解析文件名获取扩展名,比如rule.json,返回json
return "json";
}
}
在“规范和重构”那一部分中,我们有讲到,为了让代码逻辑更加清晰,可读性更好,我们要善于将功能独立的代码块封装成函数。按照这个设计思路,我们可以将代码中涉及parser创建的部分逻辑剥离出来,抽象成createParser()函数。重构之后的代码如下所示:
public RuleConfig load(String ruleConfigFilePath) {
String ruleConfigFileExtension = getFileExtension(ruleConfigFilePath);
IRuleConfigParser parser = createParser(ruleConfigFileExtension);
if (parser == null) {
throw new InvalidRuleConfigException(
"Rule config file format is not supported: " + ruleConfigFilePath);
}
String configText = "";
//从ruleConfigFilePath文件中读取配置文本到configText中
RuleConfig ruleConfig = parser.parse(configText);
return ruleConfig;
}
private String getFileExtension(String filePath) {
//...解析文件名获取扩展名,比如rule.json,返回json
return "json";
}
private IRuleConfigParser createParser(String configFormat) {
IRuleConfigParser parser = null;
if ("json".equalsIgnoreCase(configFormat)) {
parser = new JsonRuleConfigParser();
} else if ("xml".equalsIgnoreCase(configFormat)) {
parser = new XmlRuleConfigParser();
} else if ("yaml".equalsIgnoreCase(configFormat)) {
parser = new YamlRuleConfigParser();
} else if ("properties".equalsIgnoreCase(configFormat)) {
parser = new PropertiesRuleConfigParser();
}
return parser;
}
}
为了让类的职责更加单一、代码更加清晰,我们还可以进一步将createParser()函数剥离到一个独立的类中,让这个类只负责对象的创建。而这个类就是我们现在要讲的简单工厂模式类。具体的代码如下所示:
public class RuleConfigSource {
public RuleConfig load(String ruleConfigFilePath) {
String ruleConfigFileExtension = getFileExtension(ruleConfigFilePath);
IRuleConfigParser parser = RuleConfigParserFactory.createParser(ruleConfigFileExtension);
if (parser == null) {
throw new InvalidRuleConfigException(
"Rule config file format is not supported: " + ruleConfigFilePath);
}
String configText = "";
//从ruleConfigFilePath文件中读取配置文本到configText中
RuleConfig ruleConfig = parser.parse(configText);
return ruleConfig;
}
private String getFileExtension(String filePath) {
//...解析文件名获取扩展名,比如rule.json,返回json
return "json";
}
}
public class RuleConfigParserFactory {
public static IRuleConfigParser createParser(String configFormat) {
IRuleConfigParser parser = null;
if ("json".equalsIgnoreCase(configFormat)) {
parser = new JsonRuleConfigParser();
} else if ("xml".equalsIgnoreCase(configFormat)) {
parser = new XmlRuleConfigParser();
} else if ("yaml".equalsIgnoreCase(configFormat)) {
parser = new YamlRuleConfigParser();
} else if ("properties".equalsIgnoreCase(configFormat)) {
parser = new PropertiesRuleConfigParser();
}
return parser;
}
}
在上面的代码实现中,我们每次调用RuleConfigParserFactory的createParser()的时候,都要创建一个新的parser。实际上,如果parser可以复用,为了节省内存和对象创建的时间,我们可以将parser事先创建好缓存起来。当调用createParser()函数的时候,我们从缓存中取出parser对象直接使用。
这有点类似单例模式和简单工厂模式的结合,具体的代码实现如下所示。在接下来的讲解中,我们把上一种实现方法叫作简单工厂模式的第一种实现方法,把下面这种实现方法叫作简单工厂模式的第二种实现方法。
public class RuleConfigParserFactory {
private static final Map<String, RuleConfigParser> cachedParsers = new HashMap<>();
static {
cachedParsers.put("json", new JsonRuleConfigParser());
cachedParsers.put("xml", new XmlRuleConfigParser());
cachedParsers.put("yaml", new YamlRuleConfigParser());
cachedParsers.put("properties", new PropertiesRuleConfigParser());
}
public static IRuleConfigParser createParser(String configFormat) {
if (configFormat == null || configFormat.isEmpty()) {
return null;//返回null还是IllegalArgumentException全凭你自己说了算
}
IRuleConfigParser parser = cachedParsers.get(configFormat.toLowerCase());
return parser;
}
}
对于上面两种简单工厂模式的实现方法,如果我们要添加新的parser,那势必要改动到RuleConfigParserFactory的代码,那这是不是违反开闭原则呢?实际上,如果不是需要频繁地添加新的parser,只是偶尔修改一下RuleConfigParserFactory代码,稍微不符合开闭原则,也是完全可以接受的。
除此之外,在RuleConfigParserFactory的第一种代码实现中,有一组if分支判断逻辑,是不是应该用多态或其他设计模式来替代呢?实际上,如果if分支并不是很多,代码中有if分支也是完全可以接受的。应用多态或设计模式来替代if分支判断逻辑,也并不是没有任何缺点的,它虽然提高了代码的扩展性,更加符合开闭原则,但也增加了类的个数,牺牲了代码的可读性。关于这一点,我们在后面章节中会详细讲到。
总结一下,尽管简单工厂模式的代码实现中,有多处if分支判断逻辑,违背开闭原则,但权衡扩展性和可读性,这样的代码实现在大多数情况下(比如,不需要频繁地添加parser,也没有太多的parser)是没有问题的。
工厂方法(Factory Method)
如果我们非得要将if分支逻辑去掉,那该怎么办呢?比较经典处理方法就是利用多态。按照多态的实现思路,对上面的代码进行重构。重构之后的代码如下所示:
public interface IRuleConfigParserFactory {
IRuleConfigParser createParser();
}
public class JsonRuleConfigParserFactory implements IRuleConfigParserFactory {
@Override
public IRuleConfigParser createParser() {
return new JsonRuleConfigParser();
}
}
public class XmlRuleConfigParserFactory implements IRuleConfigParserFactory {
@Override
public IRuleConfigParser createParser() {
return new XmlRuleConfigParser();
}
}
public class YamlRuleConfigParserFactory implements IRuleConfigParserFactory {
@Override
public IRuleConfigParser createParser() {
return new YamlRuleConfigParser();
}
}
public class PropertiesRuleConfigParserFactory implements IRuleConfigParserFactory {
@Override
public IRuleConfigParser createParser() {
return new PropertiesRuleConfigParser();
}
}
实际上,这就是工厂方法模式的典型代码实现。这样当我们新增一种parser的时候,只需要新增一个实现了IRuleConfigParserFactory接口的Factory类即可。所以,工厂方法模式比起简单工厂模式更加符合开闭原则。
从上面的工厂方法的实现来看,一切都很完美,但是实际上存在挺大的问题。问题存在于这些工厂类的使用上。接下来,我们看一下,如何用这些工厂类来实现RuleConfigSource的load()函数。具体的代码如下所示:
public class RuleConfigSource {
public RuleConfig load(String ruleConfigFilePath) {
String ruleConfigFileExtension = getFileExtension(ruleConfigFilePath);
IRuleConfigParserFactory parserFactory = null;
if ("json".equalsIgnoreCase(ruleConfigFileExtension)) {
parserFactory = new JsonRuleConfigParserFactory();
} else if ("xml".equalsIgnoreCase(ruleConfigFileExtension)) {
parserFactory = new XmlRuleConfigParserFactory();
} else if ("yaml".equalsIgnoreCase(ruleConfigFileExtension)) {
parserFactory = new YamlRuleConfigParserFactory();
} else if ("properties".equalsIgnoreCase(ruleConfigFileExtension)) {
parserFactory = new PropertiesRuleConfigParserFactory();
} else {
throw new InvalidRuleConfigException("Rule config file format is not supported: " + ruleConfigFilePath);
}
IRuleConfigParser parser = parserFactory.createParser();
String configText = "";
//从ruleConfigFilePath文件中读取配置文本到configText中
RuleConfig ruleConfig = parser.parse(configText);
return ruleConfig;
}
private String getFileExtension(String filePath) {
//...解析文件名获取扩展名,比如rule.json,返回json
return "json";
}
}
从上面的代码实现来看,工厂类对象的创建逻辑又耦合进了load()函数中,跟我们最初的代码版本非常相似,引入工厂方法非但没有解决问题,反倒让设计变得更加复杂了。那怎么来解决这个问题呢?
**我们可以为工厂类再创建一个简单工厂,也就是工厂的工厂,用来创建工厂类对象。**这段话听起来有点绕,我把代码实现出来了,你一看就能明白了。其中,RuleConfigParserFactoryMap类是创建工厂对象的工厂类,getParserFactory()返回的是缓存好的单例工厂对象。
public class RuleConfigSource {
public RuleConfig load(String ruleConfigFilePath) {
String ruleConfigFileExtension = getFileExtension(ruleConfigFilePath);
IRuleConfigParserFactory parserFactory = RuleConfigParserFactoryMap.getParserFactory(ruleConfigFileExtension);
if (parserFactory == null) {
throw new InvalidRuleConfigException("Rule config file format is not supported: " + ruleConfigFilePath);
}
IRuleConfigParser parser = parserFactory.createParser();
String configText = "";
//从ruleConfigFilePath文件中读取配置文本到configText中
RuleConfig ruleConfig = parser.parse(configText);
return ruleConfig;
}
private String getFileExtension(String filePath) {
//...解析文件名获取扩展名,比如rule.json,返回json
return "json";
}
}
//因为工厂类只包含方法,不包含成员变量,完全可以复用,
//不需要每次都创建新的工厂类对象,所以,简单工厂模式的第二种实现思路更加合适。
public class RuleConfigParserFactoryMap { //工厂的工厂
private static final Map<String, IRuleConfigParserFactory> cachedFactories = new HashMap<>();
static {
cachedFactories.put("json", new JsonRuleConfigParserFactory());
cachedFactories.put("xml", new XmlRuleConfigParserFactory());
cachedFactories.put("yaml", new YamlRuleConfigParserFactory());
cachedFactories.put("properties", new PropertiesRuleConfigParserFactory());
}
public static IRuleConfigParserFactory getParserFactory(String type) {
if (type == null || type.isEmpty()) {
return null;
}
IRuleConfigParserFactory parserFactory = cachedFactories.get(type.toLowerCase());
return parserFactory;
}
}
当我们需要添加新的规则配置解析器的时候,我们只需要创建新的parser类和parser factory类,并且在RuleConfigParserFactoryMap类中,将新的parser factory对象添加到cachedFactories中即可。代码的改动非常少,基本上符合开闭原则。
实际上,对于规则配置文件解析这个应用场景来说,工厂模式需要额外创建诸多Factory类,也会增加代码的复杂性,而且,每个Factory类只是做简单的new操作,功能非常单薄(只有一行代码),也没必要设计成独立的类,所以,在这个应用场景下,简单工厂模式简单好用,比工厂方法模式更加合适。
那什么时候该用工厂方法模式,而非简单工厂模式呢?
我们前面提到,之所以将某个代码块剥离出来,独立为函数或者类,原因是这个代码块的逻辑过于复杂,剥离之后能让代码更加清晰,更加可读、可维护。但是,如果代码块本身并不复杂,就几行代码而已,我们完全没必要将它拆分成单独的函数或者类。
基于这个设计思想,当对象的创建逻辑比较复杂,不只是简单的new一下就可以,而是要组合其他类对象,做各种初始化操作的时候,我们推荐使用工厂方法模式,将复杂的创建逻辑拆分到多个工厂类中,让每个工厂类都不至于过于复杂。而使用简单工厂模式,将所有的创建逻辑都放到一个工厂类中,会导致这个工厂类变得很复杂。
除此之外,在某些场景下,如果对象不可复用,那工厂类每次都要返回不同的对象。如果我们使用简单工厂模式来实现,就只能选择第一种包含if分支逻辑的实现方式。如果我们还想避免烦人的if-else分支逻辑,这个时候,我们就推荐使用工厂方法模式。
抽象工厂(Abstract Factory)
讲完了简单工厂、工厂方法,我们再来看抽象工厂模式。抽象工厂模式的应用场景比较特殊,没有前两种常用,所以不是我们本节课学习的重点,你简单了解一下就可以了。
在简单工厂和工厂方法中,类只有一种分类方式。比如,在规则配置解析那个例子中,解析器类只会根据配置文件格式(Json、Xml、Yaml……)来分类。但是,如果类有两种分类方式,比如,我们既可以按照配置文件格式来分类,也可以按照解析的对象(Rule规则配置还是System系统配置)来分类,那就会对应下面这8个parser类。
针对规则配置的解析器:基于接口IRuleConfigParser
JsonRuleConfigParser
XmlRuleConfigParser
YamlRuleConfigParser
PropertiesRuleConfigParser
针对系统配置的解析器:基于接口ISystemConfigParser
JsonSystemConfigParser
XmlSystemConfigParser
YamlSystemConfigParser
PropertiesSystemConfigParser
针对这种特殊的场景,如果还是继续用工厂方法来实现的话,我们要针对每个parser都编写一个工厂类,也就是要编写8个工厂类。如果我们未来还需要增加针对业务配置的解析器(比如IBizConfigParser),那就要再对应地增加4个工厂类。而我们知道,过多的类也会让系统难维护。这个问题该怎么解决呢?
抽象工厂就是针对这种非常特殊的场景而诞生的。我们可以让一个工厂负责创建多个不同类型的对象(IRuleConfigParser、ISystemConfigParser等),而不是只创建一种parser对象。这样就可以有效地减少工厂类的个数。具体的代码实现如下所示:
public interface IConfigParserFactory {
IRuleConfigParser createRuleParser();
ISystemConfigParser createSystemParser();
//此处可以扩展新的parser类型,比如IBizConfigParser
}
public class JsonConfigParserFactory implements IConfigParserFactory {
@Override
public IRuleConfigParser createRuleParser() {
return new JsonRuleConfigParser();
}
@Override
public ISystemConfigParser createSystemParser() {
return new JsonSystemConfigParser();
}
}
public class XmlConfigParserFactory implements IConfigParserFactory {
@Override
public IRuleConfigParser createRuleParser() {
return new XmlRuleConfigParser();
}
@Override
public ISystemConfigParser createSystemParser() {
return new XmlSystemConfigParser();
}
}
// 省略YamlConfigParserFactory和PropertiesConfigParserFactory代码
如何设计实现一个Dependency Injection框架?
依赖注入框架,或者叫依赖注入容器(Dependency Injection Container),简称DI容器。
工厂模式和DI容器有何区别?
实际上,DI容器底层最基本的设计思路就是基于工厂模式的。DI容器相当于一个大的工厂类,负责在程序启动的时候,根据配置(要创建哪些类对象,每个类对象的创建需要依赖哪些其他类对象)事先创建好对象。当应用程序需要使用某个类对象的时候,直接从容器中获取即可。正是因为它持有一堆对象,所以这个框架才被称为“容器”。
DI容器相对于我们上节课讲的工厂模式的例子来说,它处理的是更大的对象创建工程。上节课讲的工厂模式中,一个工厂类只负责某个类对象或者某一组相关类对象(继承自同一抽象类或者接口的子类)的创建,而DI容器负责的是整个应用中所有类对象的创建。
除此之外,DI容器负责的事情要比单纯的工厂模式要多。比如,它还包括配置的解析、对象生命周期的管理。
DI容器的核心功能有哪些?
总结一下,一个简单的DI容器的核心功能一般有三个:配置解析、对象创建和对象生命周期管理。
首先,我们来看配置解析。
在上节课讲的工厂模式中,工厂类要创建哪个类对象是事先确定好的,并且是写死在工厂类代码中的。作为一个通用的框架来说,框架代码跟应用代码应该是高度解耦的,DI容器事先并不知道应用会创建哪些对象,不可能把某个应用要创建的对象写死在框架代码中。所以,我们需要通过一种形式,让应用告知DI容器要创建哪些对象。这种形式就是我们要讲的配置。
我们将需要由DI容器来创建的类对象和创建类对象的必要信息(使用哪个构造函数以及对应的构造函数参数都是什么等等),放到配置文件中。容器读取配置文件,根据配置文件提供的信息来创建对象。
下面是一个典型的Spring容器的配置文件。Spring容器读取这个配置文件,解析出要创建的两个对象:rateLimiter和redisCounter,并且得到两者的依赖关系:rateLimiter依赖redisCounter。
public class RateLimiter {
private RedisCounter redisCounter;
public RateLimiter(RedisCounter redisCounter) {
this.redisCounter = redisCounter;
}
public void test() {
System.out.println("Hello World!");
}
//...
}
public class RedisCounter {
private String ipAddress;
private int port;
public RedisCounter(String ipAddress, int port) {
this.ipAddress = ipAddress;
this.port = port;
}
//...
}
配置文件beans.xml:
<beans>
<bean id="rateLimiter" class="com.xzg.RateLimiter">
<constructor-arg ref="redisCounter"/>
</bean>
<bean id="redisCounter" class="com.xzg.redisCounter">
<constructor-arg type="String" value="127.0.0.1">
<constructor-arg type="int" value=1234>
</bean>
</beans>
其次,我们再来看对象创建。
在DI容器中,如果我们给每个类都对应创建一个工厂类,那项目中类的个数会成倍增加,这会增加代码的维护成本。要解决这个问题并不难。我们只需要将所有类对象的创建都放到一个工厂类中完成就可以了,比如BeansFactory。
你可能会说,如果要创建的类对象非常多,BeansFactory中的代码会不会线性膨胀(代码量跟创建对象的个数成正比)呢?实际上并不会。待会讲到DI容器的具体实现的时候,我们会讲“反射”这种机制,它能在程序运行的过程中,动态地加载类、创建对象,不需要事先在代码中写死要创建哪些对象。所以,不管是创建一个对象还是十个对象,BeansFactory工厂类代码都是一样的。
最后,我们来看对象的生命周期管理。
上一节课我们讲到,简单工厂模式有两种实现方式,一种是每次都返回新创建的对象,另一种是每次都返回同一个事先创建好的对象,也就是所谓的单例对象。在Spring框架中,我们可以通过配置scope属性,来区分这两种不同类型的对象。scope=prototype表示返回新创建的对象,scope=singleton表示返回单例对象。
除此之外,我们还可以配置对象是否支持懒加载。如果lazy-init=true,对象在真正被使用到的时候(比如:BeansFactory.getBean(“userService”))才被被创建;如果lazy-init=false,对象在应用启动的时候就事先创建好。
不仅如此,我们还可以配置对象的init-method和destroy-method方法,比如init-method=loadProperties(),destroy-method=updateConfigFile()。DI容器在创建好对象之后,会主动调用init-method属性指定的方法来初始化对象。在对象被最终销毁之前,DI容器会主动调用destroy-method属性指定的方法来做一些清理工作,比如释放数据库连接池、关闭文件。
实现一个简单的DI容器
实际上,用Java语言来实现一个简单的DI容器,核心逻辑只需要包括这样两个部分:配置文件解析、根据配置文件通过“反射”语法来创建对象。
1.最小原型设计
因为我们主要是讲解设计模式,所以,在今天的讲解中,我们只实现一个DI容器的最小原型。像Spring框架这样的DI容器,它支持的配置格式非常灵活和复杂。为了简化代码实现,重点讲解原理,在最小原型中,我们只支持下面配置文件中涉及的配置语法。
配置文件beans.xml
<beans>
<bean id="rateLimiter" class="com.xzg.RateLimiter">
<constructor-arg ref="redisCounter"/>
</bean>
<bean id="redisCounter" class="com.xzg.redisCounter" scope="singleton" lazy-init="true">
<constructor-arg type="String" value="127.0.0.1">
<constructor-arg type="int" value=1234>
</bean>
</bean
最小原型的使用方式跟Spring框架非常类似,示例代码如下所示:
public class Demo {
public static void main(String[] args) {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(
"beans.xml");
RateLimiter rateLimiter = (RateLimiter) applicationContext.getBean("rateLimiter");
rateLimiter.test();
//...
}
}
2.提供执行入口
前面我们讲到,面向对象设计的最后一步是:组装类并提供执行入口。在这里,执行入口就是一组暴露给外部使用的接口和类。
通过刚刚的最小原型使用示例代码,我们可以看出,执行入口主要包含两部分:ApplicationContext和ClassPathXmlApplicationContext。其中,ApplicationContext是接口,ClassPathXmlApplicationContext是接口的实现类。两个类具体实现如下所示:
public interface ApplicationContext {
Object getBean(String beanId);
}
public class ClassPathXmlApplicationContext implements ApplicationContext {
private BeansFactory beansFactory;
private BeanConfigParser beanConfigParser;
public ClassPathXmlApplicationContext(String configLocation) {
this.beansFactory = new BeansFactory();
this.beanConfigParser = new XmlBeanConfigParser();
loadBeanDefinitions(configLocation);
}
private void loadBeanDefinitions(String configLocation) {
InputStream in = null;
try {
in = this.getClass().getResourceAsStream("/" + configLocation);
if (in == null) {
throw new RuntimeException("Can not find config file: " + configLocation);
}
List<BeanDefinition> beanDefinitions = beanConfigParser.parse(in);
beansFactory.addBeanDefinitions(beanDefinitions);
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
// TODO: log error
}
}
}
}
@Override
public Object getBean(String beanId) {
return beansFactory.getBean(beanId);
}
}
从上面的代码中,我们可以看出,ClassPathXmlApplicationContext负责组装BeansFactory和BeanConfigParser两个类,串联执行流程:从classpath中加载XML格式的配置文件,通过BeanConfigParser解析为统一的BeanDefinition格式,然后,BeansFactory根据BeanDefinition来创建对象。
3.配置文件解析
配置文件解析主要包含BeanConfigParser接口和XmlBeanConfigParser实现类,负责将配置文件解析为BeanDefinition结构,以便BeansFactory根据这个结构来创建对象。
配置文件的解析比较繁琐,不涉及我们专栏要讲的理论知识,不是我们讲解的重点,所以这里我只给出两个类的大致设计思路,并未给出具体的实现代码。如果感兴趣的话,你可以自行补充完整。具体的代码框架如下所示:
public interface BeanConfigParser {
List<BeanDefinition> parse(InputStream inputStream);
List<BeanDefinition> parse(String configContent);
}
public class XmlBeanConfigParser implements BeanConfigParser {
@Override
public List<BeanDefinition> parse(InputStream inputStream) {
String content = null;
// TODO:...
return parse(content);
}
@Override
public List<BeanDefinition> parse(String configContent) {
List<BeanDefinition> beanDefinitions = new ArrayList<>();
// TODO:...
return beanDefinitions;
}
}
public class BeanDefinition {
private String id;
private String className;
private List<ConstructorArg> constructorArgs = new ArrayList<>();
private Scope scope = Scope.SINGLETON;
private boolean lazyInit = false;
// 省略必要的getter/setter/constructors
public boolean isSingleton() {
return scope.equals(Scope.SINGLETON);
}
public static enum Scope {
SINGLETON,
PROTOTYPE
}
public static class ConstructorArg {
private boolean isRef;
private Class type;
private Object arg;
// 省略必要的getter/setter/constructors
}
}
4.核心工厂类设计
最后,我们来看,BeansFactory是如何设计和实现的。这也是我们这个DI容器最核心的一个类了。它负责根据从配置文件解析得到的BeanDefinition来创建对象。
如果对象的scope属性是singleton,那对象创建之后会缓存在singletonObjects这样一个map中,下次再请求此对象的时候,直接从map中取出返回,不需要重新创建。如果对象的scope属性是prototype,那每次请求对象,BeansFactory都会创建一个新的对象返回。
实际上,BeansFactory创建对象用到的主要技术点就是Java中的反射语法:一种动态加载类和创建对象的机制。我们知道,JVM在启动的时候会根据代码自动地加载类、创建对象。至于都要加载哪些类、创建哪些对象,这些都是在代码中写死的,或者说提前写好的。但是,如果某个对象的创建并不是写死在代码中,而是放到配置文件中,我们需要在程序运行期间,动态地根据配置文件来加载类、创建对象,那这部分工作就没法让JVM帮我们自动完成了,我们需要利用Java提供的反射语法自己去编写代码。
搞清楚了反射的原理,BeansFactory的代码就不难看懂了。具体代码实现如下所示:
public class BeansFactory {
private ConcurrentHashMap<String, Object> singletonObjects = new ConcurrentHashMap<>();
private ConcurrentHashMap<String, BeanDefinition> beanDefinitions = new ConcurrentHashMap<>();
public void addBeanDefinitions(List<BeanDefinition> beanDefinitionList) {
for (BeanDefinition beanDefinition : beanDefinitionList) {
this.beanDefinitions.putIfAbsent(beanDefinition.getId(), beanDefinition);
}
for (BeanDefinition beanDefinition : beanDefinitionList) {
if (beanDefinition.isLazyInit() == false && beanDefinition.isSingleton()) {
createBean(beanDefinition);
}
}
}
public Object getBean(String beanId) {
BeanDefinition beanDefinition = beanDefinitions.get(beanId);
if (beanDefinition == null) {
throw new NoSuchBeanDefinitionException("Bean is not defined: " + beanId);
}
return createBean(beanDefinition);
}
@VisibleForTesting
protected Object createBean(BeanDefinition beanDefinition) {
if (beanDefinition.isSingleton() && singletonObjects.contains(beanDefinition.getId())) {
return singletonObjects.get(beanDefinition.getId());
}
Object bean = null;
try {
Class beanClass = Class.forName(beanDefinition.getClassName());
List<BeanDefinition.ConstructorArg> args = beanDefinition.getConstructorArgs();
if (args.isEmpty()) {
bean = beanClass.newInstance();
} else {
Class[] argClasses = new Class[args.size()];
Object[] argObjects = new Object[args.size()];
for (int i = 0; i < args.size(); ++i) {
BeanDefinition.ConstructorArg arg = args.get(i);
if (!arg.getIsRef()) {
argClasses[i] = arg.getType();
argObjects[i] = arg.getArg();
} else {
BeanDefinition refBeanDefinition = beanDefinitions.get(arg.getArg());
if (refBeanDefinition == null) {
throw new NoSuchBeanDefinitionException("Bean is not defined: " + arg.getArg());
}
argClasses[i] = Class.forName(refBeanDefinition.getClassName());
argObjects[i] = createBean(refBeanDefinition);
}
}
bean = beanClass.getConstructor(argClasses).newInstance(argObjects);
}
} catch (ClassNotFoundException | IllegalAccessException
| InstantiationException | NoSuchMethodException | InvocationTargetException e) {
throw new BeanCreationFailureException("", e);
}
if (bean != null && beanDefinition.isSingleton()) {
singletonObjects.putIfAbsent(beanDefinition.getId(), bean);
return singletonObjects.get(beanDefinition.getId());
}
return bean;
}
}
建造者模式
Builder模式,中文翻译为建造者模式或者构建者模式,也有人叫它生成器模式。
why
在平时的开发中,创建一个对象最常用的方式是,使用new关键字调用类的构造函数来完成。我的问题是,什么情况下这种方式就不适用了,就需要采用建造者模式来创建对象呢?你可以先思考一下,下面我通过一个例子来带你看一下。
假设有这样一道设计面试题:我们需要定义一个资源池配置类ResourcePoolConfig。这里的资源池,你可以简单理解为线程池、连接池、对象池等。在这个资源池配置类中,有以下几个成员变量,也就是可配置项。现在,请你编写代码实现这个ResourcePoolConfig类。
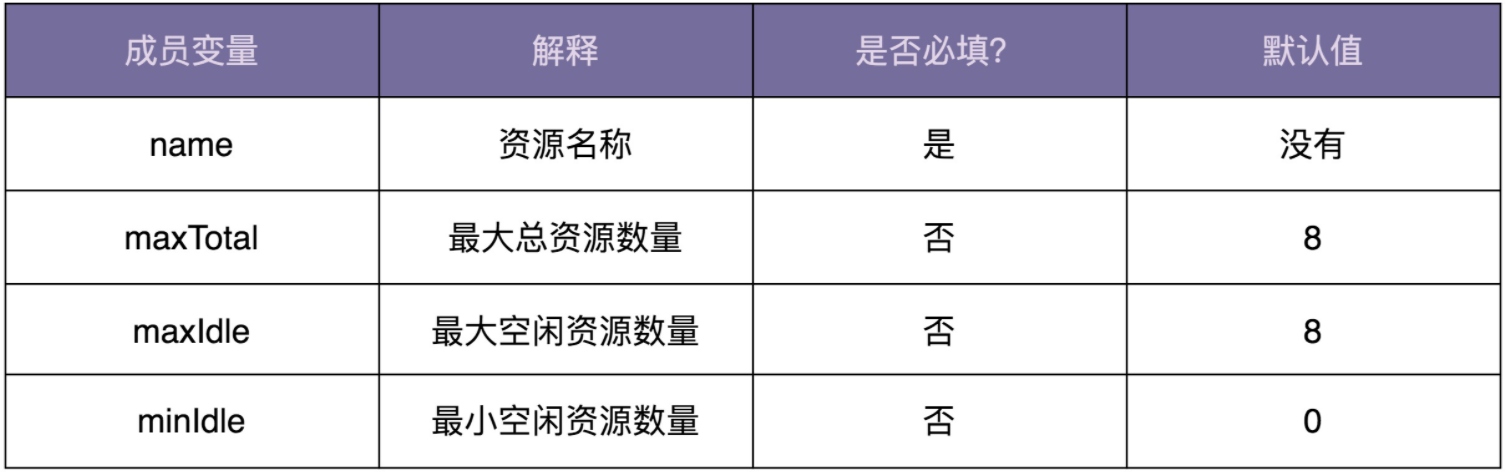
只要你稍微有点开发经验,那实现这样一个类对你来说并不是件难事。最常见、最容易想到的实现思路如下代码所示。因为maxTotal、maxIdle、minIdle不是必填变量,所以在创建ResourcePoolConfig对象的时候,我们通过往构造函数中,给这几个参数传递null值,来表示使用默认值。
public class ResourcePoolConfig {
private static final int DEFAULT_MAX_TOTAL = 8;
private static final int DEFAULT_MAX_IDLE = 8;
private static final int DEFAULT_MIN_IDLE = 0;
private String name;
private int maxTotal = DEFAULT_MAX_TOTAL;
private int maxIdle = DEFAULT_MAX_IDLE;
private int minIdle = DEFAULT_MIN_IDLE;
public ResourcePoolConfig(String name, Integer maxTotal, Integer maxIdle, Integer minIdle) {
if (StringUtils.isBlank(name)) {
throw new IllegalArgumentException("name should not be empty.");
}
this.name = name;
if (maxTotal != null) {
if (maxTotal <= 0) {
throw new IllegalArgumentException("maxTotal should be positive.");
}
this.maxTotal = maxTotal;
}
if (maxIdle != null) {
if (maxIdle < 0) {
throw new IllegalArgumentException("maxIdle should not be negative.");
}
this.maxIdle = maxIdle;
}
if (minIdle != null) {
if (minIdle < 0) {
throw new IllegalArgumentException("minIdle should not be negative.");
}
this.minIdle = minIdle;
}
}
//...省略getter方法...
}
现在,ResourcePoolConfig只有4个可配置项,对应到构造函数中,也只有4个参数,参数的个数不多。但是,如果可配置项逐渐增多,变成了8个、10个,甚至更多,那继续沿用现在的设计思路,构造函数的参数列表会变得很长,代码在可读性和易用性上都会变差。在使用构造函数的时候,我们就容易搞错各参数的顺序,传递进错误的参数值,导致非常隐蔽的bug。
// 参数太多,导致可读性差、参数可能传递错误
ResourcePoolConfig config = new ResourcePoolConfig("dbconnectionpool", 16, null, 8, null, false , true, 10, 20,false, true);
解决这个问题的办法你应该也已经想到了,那就是用set()函数来给成员变量赋值,以替代冗长的构造函数。我们直接看代码,具体如下所示。其中,配置项name是必填的,所以我们把它放到构造函数中设置,强制创建类对象的时候就要填写。其他配置项maxTotal、maxIdle、minIdle都不是必填的,所以我们通过set()函数来设置,让使用者自主选择填写或者不填写。
public class ResourcePoolConfig {
private static final int DEFAULT_MAX_TOTAL = 8;
private static final int DEFAULT_MAX_IDLE = 8;
private static final int DEFAULT_MIN_IDLE = 0;
private String name;
private int maxTotal = DEFAULT_MAX_TOTAL;
private int maxIdle = DEFAULT_MAX_IDLE;
private int minIdle = DEFAULT_MIN_IDLE;
public ResourcePoolConfig(String name) {
if (StringUtils.isBlank(name)) {
throw new IllegalArgumentException("name should not be empty.");
}
this.name = name;
}
public void setMaxTotal(int maxTotal) {
if (maxTotal <= 0) {
throw new IllegalArgumentException("maxTotal should be positive.");
}
this.maxTotal = maxTotal;
}
public void setMaxIdle(int maxIdle) {
if (maxIdle < 0) {
throw new IllegalArgumentException("maxIdle should not be negative.");
}
this.maxIdle = maxIdle;
}
public void setMinIdle(int minIdle) {
if (minIdle < 0) {
throw new IllegalArgumentException("minIdle should not be negative.");
}
this.minIdle = minIdle;
}
//...省略getter方法...
}
接下来,我们来看新的ResourcePoolConfig类该如何使用。我写了一个示例代码,如下所示。没有了冗长的函数调用和参数列表,代码在可读性和易用性上提高了很多。
// ResourcePoolConfig使用举例
ResourcePoolConfig config = new ResourcePoolConfig("dbconnectionpool");
config.setMaxTotal(16);
config.setMaxIdle(8);
至此,我们仍然没有用到建造者模式,通过构造函数设置必填项,通过set()方法设置可选配置项,就能实现我们的设计需求。如果我们把问题的难度再加大点,比如,还需要解决下面这三个问题,那现在的设计思路就不能满足了。
- 我们刚刚讲到,name是必填的,所以,我们把它放到构造函数中,强制创建对象的时候就设置。如果必填的配置项有很多,把这些必填配置项都放到构造函数中设置,那构造函数就又会出现参数列表很长的问题。如果我们把必填项也通过set()方法设置,那校验这些必填项是否已经填写的逻辑就无处安放了。
- 除此之外,假设配置项之间有一定的依赖关系,比如,如果用户设置了maxTotal、maxIdle、minIdle其中一个,就必须显式地设置另外两个;或者配置项之间有一定的约束条件,比如,maxIdle和minIdle要小于等于maxTotal。如果我们继续使用现在的设计思路,那这些配置项之间的依赖关系或者约束条件的校验逻辑就无处安放了。
- 如果我们希望ResourcePoolConfig类对象是不可变对象,也就是说,对象在创建好之后,就不能再修改内部的属性值。要实现这个功能,我们就不能在ResourcePoolConfig类中暴露set()方法。
为了解决这些问题,建造者模式就派上用场了。
how
我们可以把校验逻辑放置到Builder类中,先创建建造者,并且通过set()方法设置建造者的变量值,然后在使用build()方法真正创建对象之前,做集中的校验,校验通过之后才会创建对象。除此之外,我们把ResourcePoolConfig的构造函数改为private私有权限。这样我们就只能通过建造者来创建ResourcePoolConfig类对象。并且,ResourcePoolConfig没有提供任何set()方法,这样我们创建出来的对象就是不可变对象了。
我们用建造者模式重新实现了上面的需求,具体的代码如下所示:
public class ResourcePoolConfig {
private String name;
private int maxTotal;
private int maxIdle;
private int minIdle;
private ResourcePoolConfig(Builder builder) {
this.name = builder.name;
this.maxTotal = builder.maxTotal;
this.maxIdle = builder.maxIdle;
this.minIdle = builder.minIdle;
}
//...省略getter方法...
//我们将Builder类设计成了ResourcePoolConfig的内部类。
//我们也可以将Builder类设计成独立的非内部类ResourcePoolConfigBuilder。
public static class Builder {
private static final int DEFAULT_MAX_TOTAL = 8;
private static final int DEFAULT_MAX_IDLE = 8;
private static final int DEFAULT_MIN_IDLE = 0;
private String name;
private int maxTotal = DEFAULT_MAX_TOTAL;
private int maxIdle = DEFAULT_MAX_IDLE;
private int minIdle = DEFAULT_MIN_IDLE;
public ResourcePoolConfig build() {
// 校验逻辑放到这里来做,包括必填项校验、依赖关系校验、约束条件校验等
if (StringUtils.isBlank(name)) {
throw new IllegalArgumentException("...");
}
if (maxIdle > maxTotal) {
throw new IllegalArgumentException("...");
}
if (minIdle > maxTotal || minIdle > maxIdle) {
throw new IllegalArgumentException("...");
}
return new ResourcePoolConfig(this);
}
public Builder setName(String name) {
if (StringUtils.isBlank(name)) {
throw new IllegalArgumentException("...");
}
this.name = name;
return this;
}
public Builder setMaxTotal(int maxTotal) {
if (maxTotal <= 0) {
throw new IllegalArgumentException("...");
}
this.maxTotal = maxTotal;
return this;
}
public Builder setMaxIdle(int maxIdle) {
if (maxIdle < 0) {
throw new IllegalArgumentException("...");
}
this.maxIdle = maxIdle;
return this;
}
public Builder setMinIdle(int minIdle) {
if (minIdle < 0) {
throw new IllegalArgumentException("...");
}
this.minIdle = minIdle;
return this;
}
}
}
// 这段代码会抛出IllegalArgumentException,因为minIdle>maxIdle
ResourcePoolConfig config = new ResourcePoolConfig.Builder()
.setName("dbconnectionpool")
.setMaxTotal(16)
.setMaxIdle(10)
.setMinIdle(12)
.build();
实际上,使用建造者模式创建对象,还能避免对象存在无效状态。我再举个例子解释一下。比如我们定义了一个长方形类,如果不使用建造者模式,采用先创建后set的方式,那就会导致在第一个set之后,对象处于无效状态。具体代码如下所示:
Rectangle r = new Rectange(); // r is invalid
r.setWidth(2); // r is invalid
r.setHeight(3); // r is valid
为了避免这种无效状态的存在,我们就需要使用构造函数一次性初始化好所有的成员变量。如果构造函数参数过多,我们就需要考虑使用建造者模式,先设置建造者的变量,然后再一次性地创建对象,让对象一直处于有效状态。
实际上,如果我们并不是很关心对象是否有短暂的无效状态,也不是太在意对象是否是可变的。比如,对象只是用来映射数据库读出来的数据,那我们直接暴露set()方法来设置类的成员变量值是完全没问题的。而且,使用建造者模式来构建对象,代码实际上是有点重复的,ResourcePoolConfig类中的成员变量,要在Builder类中重新再定义一遍。
实际上,使用建造者模式创建对象,还能避免对象存在无效状态。我再举个例子解释一下。比如我们定义了一个长方形类,如果不使用建造者模式,采用先创建后set的方式,那就会导致在第一个set之后,对象处于无效状态。具体代码如下所示:
Rectangle r = new Rectange(); // r is invalid
r.setWidth(2); // r is invalid
r.setHeight(3); // r is valid
为了避免这种无效状态的存在,我们就需要使用构造函数一次性初始化好所有的成员变量。如果构造函数参数过多,我们就需要考虑使用建造者模式,先设置建造者的变量,然后再一次性地创建对象,让对象一直处于有效状态。
实际上,如果我们并不是很关心对象是否有短暂的无效状态,也不是太在意对象是否是可变的。比如,对象只是用来映射数据库读出来的数据,那我们直接暴露set()方法来设置类的成员变量值是完全没问题的。而且,使用建造者模式来构建对象,代码实际上是有点重复的,ResourcePoolConfig类中的成员变量,要在Builder类中重新再定义一遍。
与工厂模式区别
实际上,工厂模式是用来创建不同但是相关类型的对象(继承同一父类或者接口的一组子类),由给定的参数来决定创建哪种类型的对象。建造者模式是用来创建一种类型的复杂对象,通过设置不同的可选参数,“定制化”地创建不同的对象。
网上有一个经典的例子很好地解释了两者的区别。
顾客走进一家餐馆点餐,我们利用工厂模式,根据用户不同的选择,来制作不同的食物,比如披萨、汉堡、沙拉。对于披萨来说,用户又有各种配料可以定制,比如奶酪、西红柿、起司,我们通过建造者模式根据用户选择的不同配料来制作披萨。
实际上,我们也不要太学院派,非得把工厂模式、建造者模式分得那么清楚,我们需要知道的是,每个模式为什么这么设计,能解决什么问题。只有了解了这些最本质的东西,我们才能不生搬硬套,才能灵活应用,甚至可以混用各种模式创造出新的模式,来解决特定场景的问题。
原型模式
原型模式的原理与应用
如果对象的创建成本比较大,而同一个类的不同对象之间差别不大(大部分字段都相同),在这种情况下,我们可以利用对已有对象(原型)进行复制(或者叫拷贝)的方式来创建新对象,以达到节省创建时间的目的。这种基于原型来创建对象的方式就叫作原型设计模式(Prototype Design Pattern),简称原型模式。
那何为“对象的创建成本比较大”?
实际上,创建对象包含的申请内存、给成员变量赋值这一过程,本身并不会花费太多时间,或者说对于大部分业务系统来说,这点时间完全是可以忽略的。应用一个复杂的模式,只得到一点点的性能提升,这就是所谓的过度设计,得不偿失。
但是,如果对象中的数据需要经过复杂的计算才能得到(比如排序、计算哈希值),或者需要从RPC、网络、数据库、文件系统等非常慢速的IO中读取,这种情况下,我们就可以利用原型模式,从其他已有对象中直接拷贝得到,而不用每次在创建新对象的时候,都重复执行这些耗时的操作。
这么说还是比较理论,接下来,我们通过一个例子来解释一下刚刚这段话。
假设数据库中存储了大约10万条“搜索关键词”信息,每条信息包含关键词、关键词被搜索的次数、信息最近被更新的时间等。系统A在启动的时候会加载这份数据到内存中,用于处理某些其他的业务需求。为了方便快速地查找某个关键词对应的信息,我们给关键词建立一个散列表索引。
如果你熟悉的是Java语言,可以直接使用语言中提供的HashMap容器来实现。其中,HashMap的key为搜索关键词,value为关键词详细信息(比如搜索次数)。我们只需要将数据从数据库中读取出来,放入HashMap就可以了。
不过,我们还有另外一个系统B,专门用来分析搜索日志,定期(比如间隔10分钟)批量地更新数据库中的数据,并且标记为新的数据版本。比如,在下面的示例图中,我们对v2版本的数据进行更新,得到v3版本的数据。这里我们假设只有更新和新添关键词,没有删除关键词的行为。
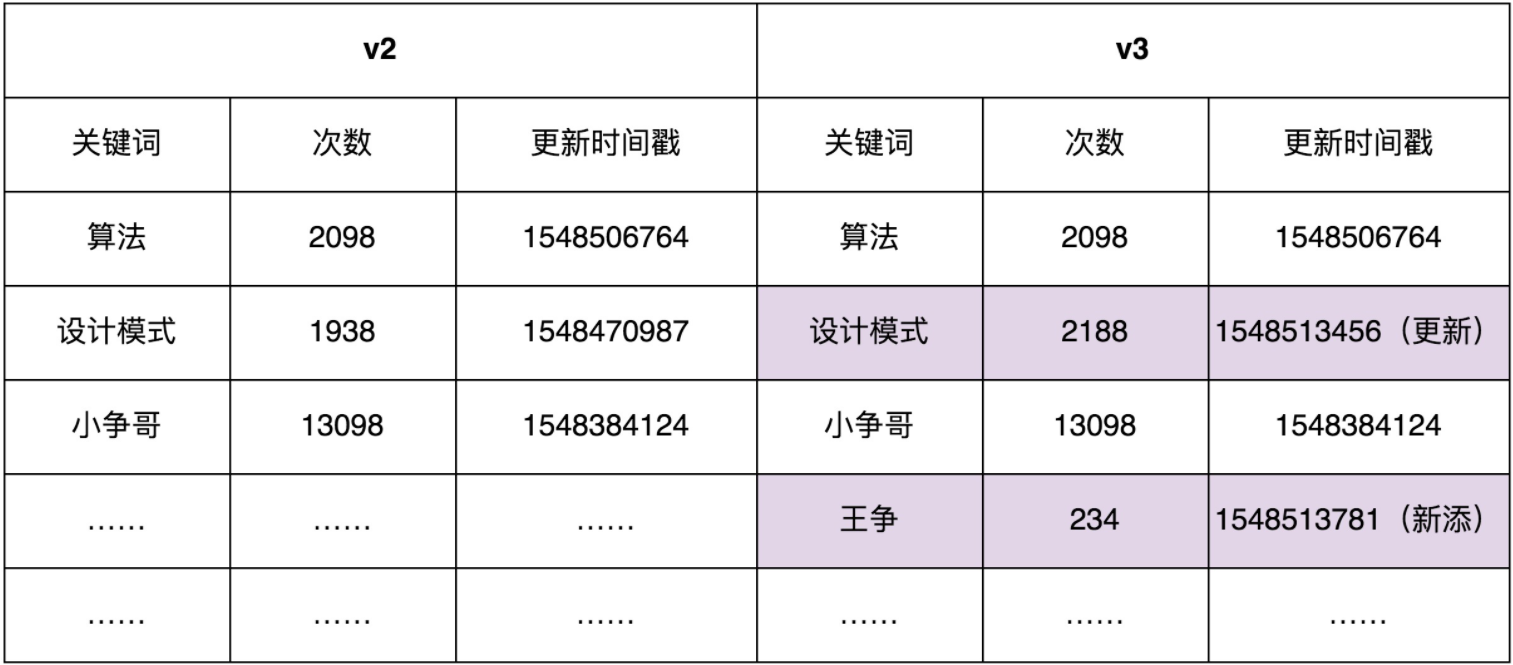
为了保证系统A中数据的实时性(不一定非常实时,但数据也不能太旧),系统A需要定期根据数据库中的数据,更新内存中的索引和数据。
我们该如何实现这个需求呢?
实际上,也不难。我们只需要在系统A中,记录当前数据的版本Va对应的更新时间Ta,从数据库中捞出更新时间大于Ta的所有搜索关键词,也就是找出Va版本与最新版本数据的“差集”,然后针对差集中的每个关键词进行处理。如果它已经在散列表中存在了,我们就更新相应的搜索次数、更新时间等信息;如果它在散列表中不存在,我们就将它插入到散列表中。
public class Demo {
private ConcurrentHashMap<String, SearchWord> currentKeywords = new ConcurrentHashMap<>();
private long lastUpdateTime = -1;
public void refresh() {
// 从数据库中取出更新时间>lastUpdateTime的数据,放入到currentKeywords中
List<SearchWord> toBeUpdatedSearchWords = getSearchWords(lastUpdateTime);
long maxNewUpdatedTime = lastUpdateTime;
for (SearchWord searchWord : toBeUpdatedSearchWords) {
if (searchWord.getLastUpdateTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = searchWord.getLastUpdateTime();
}
if (currentKeywords.containsKey(searchWord.getKeyword())) {
currentKeywords.replace(searchWord.getKeyword(), searchWord);
} else {
currentKeywords.put(searchWord.getKeyword(), searchWord);
}
}
lastUpdateTime = maxNewUpdatedTime;
}
private List<SearchWord> getSearchWords(long lastUpdateTime) {
// TODO: 从数据库中取出更新时间>lastUpdateTime的数据
return null;
}
}
不过,现在,我们有一个特殊的要求:任何时刻,系统A中的所有数据都必须是同一个版本的,要么都是版本a,要么都是版本b,不能有的是版本a,有的是版本b。那刚刚的更新方式就不能满足这个要求了。除此之外,我们还要求:在更新内存数据的时候,系统A不能处于不可用状态,也就是不能停机更新数据。
那我们该如何实现现在这个需求呢?
实际上,也不难。我们把正在使用的数据的版本定义为“服务版本”,当我们要更新内存中的数据的时候,我们并不是直接在服务版本(假设是版本a数据)上更新,而是重新创建另一个版本数据(假设是版本b数据),等新的版本数据建好之后,再一次性地将服务版本从版本a切换到版本b。这样既保证了数据一直可用,又避免了中间状态的存在。
public class Demo {
private HashMap<String, SearchWord> currentKeywords=new HashMap<>();
public void refresh() {
HashMap<String, SearchWord> newKeywords = new LinkedHashMap<>();
// 从数据库中取出所有的数据,放入到newKeywords中
List<SearchWord> toBeUpdatedSearchWords = getSearchWords();
for (SearchWord searchWord : toBeUpdatedSearchWords) {
newKeywords.put(searchWord.getKeyword(), searchWord);
}
currentKeywords = newKeywords;
}
private List<SearchWord> getSearchWords() {
// TODO: 从数据库中取出所有的数据
return null;
}
}
不过,在上面的代码实现中,newKeywords构建的成本比较高。我们需要将这10万条数据从数据库中读出,然后计算哈希值,构建newKeywords。这个过程显然是比较耗时。为了提高效率,原型模式就派上用场了。
我们拷贝currentKeywords数据到newKeywords中,然后从数据库中只捞出新增或者有更新的关键词,更新到newKeywords中。而相对于10万条数据来说,每次新增或者更新的关键词个数是比较少的,所以,这种策略大大提高了数据更新的效率。
按照这个设计思路,我给出的示例代码如下所示:
public class Demo {
private HashMap<String, SearchWord> currentKeywords=new HashMap<>();
private long lastUpdateTime = -1;
public void refresh() {
// 原型模式就这么简单,拷贝已有对象的数据,更新少量差值
HashMap<String, SearchWord> newKeywords = (HashMap<String, SearchWord>) currentKeywords.clone();
// 从数据库中取出更新时间>lastUpdateTime的数据,放入到newKeywords中
List<SearchWord> toBeUpdatedSearchWords = getSearchWords(lastUpdateTime);
long maxNewUpdatedTime = lastUpdateTime;
for (SearchWord searchWord : toBeUpdatedSearchWords) {
if (searchWord.getLastUpdateTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = searchWord.getLastUpdateTime();
}
if (newKeywords.containsKey(searchWord.getKeyword())) {
SearchWord oldSearchWord = newKeywords.get(searchWord.getKeyword());
oldSearchWord.setCount(searchWord.getCount());
oldSearchWord.setLastUpdateTime(searchWord.getLastUpdateTime());
} else {
newKeywords.put(searchWord.getKeyword(), searchWord);
}
}
lastUpdateTime = maxNewUpdatedTime;
currentKeywords = newKeywords;
}
private List<SearchWord> getSearchWords(long lastUpdateTime) {
// TODO: 从数据库中取出更新时间>lastUpdateTime的数据
return null;
}
}
这里我们利用了Java中的clone()语法来复制一个对象。如果你熟悉的语言没有这个语法,那把数据从currentKeywords中一个个取出来,然后再重新计算哈希值,放入到newKeywords中也是可以接受的。毕竟,最耗时的还是从数据库中取数据的操作。相对于数据库的IO操作来说,内存操作和CPU计算的耗时都是可以忽略的。
不过,不知道你有没有发现,实际上,刚刚的代码实现是有问题的。要弄明白到底有什么问题,我们需要先了解另外两个概念:深拷贝(Deep Copy)和浅拷贝(Shallow Copy)。
原型模式的实现方式:深拷贝和浅拷贝
在内存中,用散列表组织的搜索关键词信息是如何存储的。我画了一张示意图,大致结构如下所示。从图中我们可以发现,散列表索引中,每个结点存储的key是搜索关键词,value是SearchWord对象的内存地址。SearchWord对象本身存储在散列表之外的内存空间中。
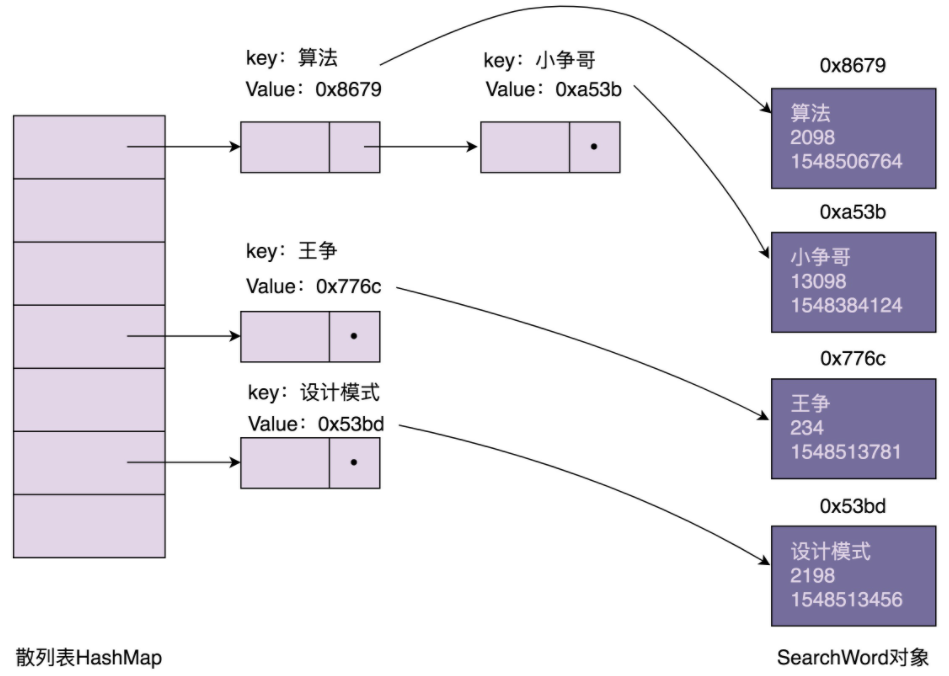
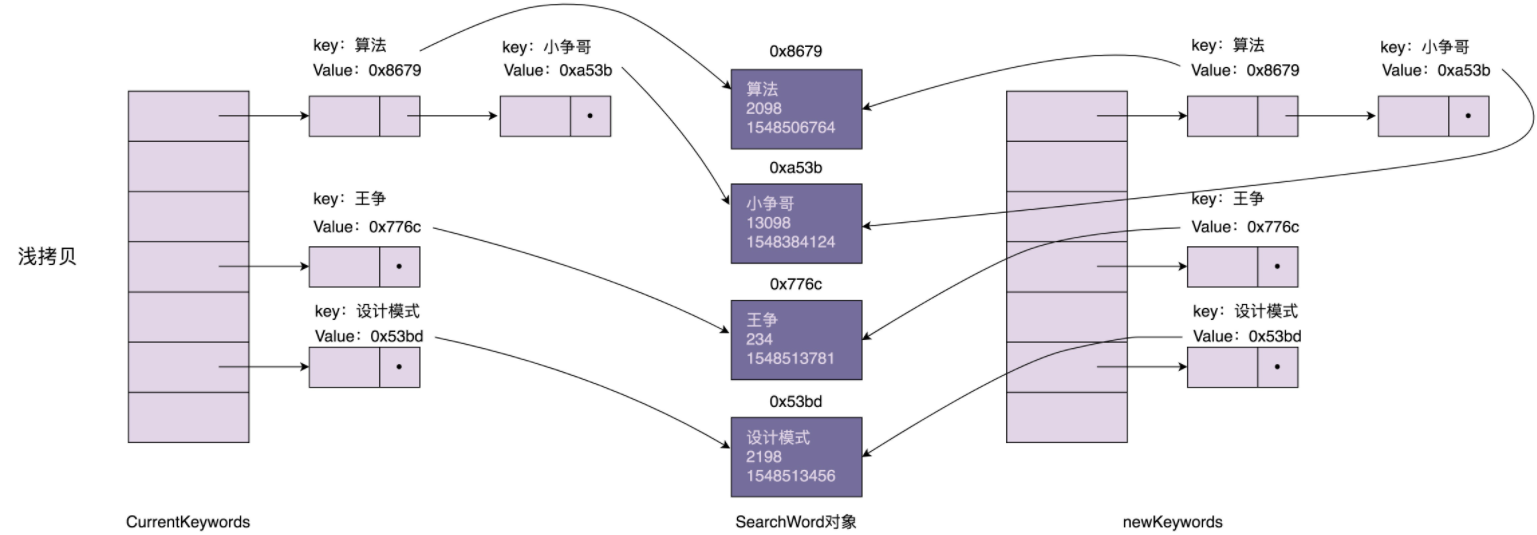
浅拷贝和深拷贝的区别在于,浅拷贝只会复制图中的索引(散列表),不会复制数据(SearchWord对象)本身。相反,深拷贝不仅仅会复制索引,还会复制数据本身。浅拷贝得到的对象(newKeywords)跟原始对象(currentKeywords)共享数据(SearchWord对象),而深拷贝得到的是一份完完全全独立的对象。具体的对比如下图所示:
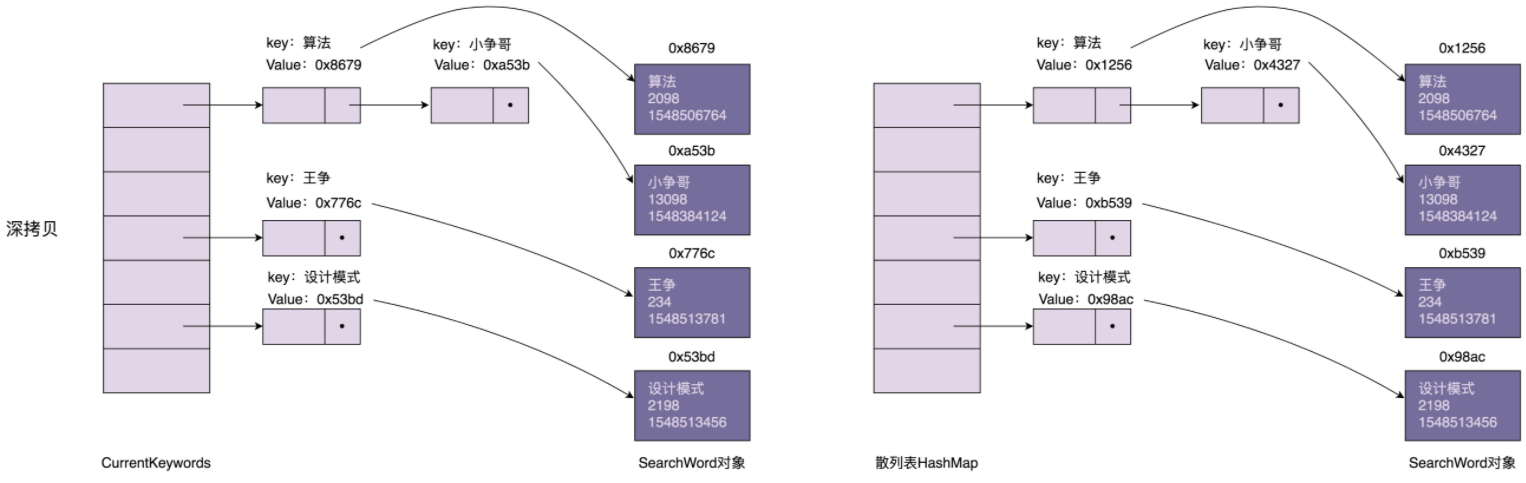
在Java语言中,Object类的clone()方法执行的就是我们刚刚说的浅拷贝。它只会拷贝对象中的基本数据类型的数据(比如,int、long),以及引用对象(SearchWord)的内存地址,不会递归地拷贝引用对象本身。
在上面的代码中,我们通过调用HashMap上的clone()浅拷贝方法来实现原型模式。当我们通过newKeywords更新SearchWord对象的时候(比如,更新“设计模式”这个搜索关键词的访问次数),newKeywords和currentKeywords因为指向相同的一组SearchWord对象,就会导致currentKeywords中指向的SearchWord,有的是老版本的,有的是新版本的,就没法满足我们之前的需求:currentKeywords中的数据在任何时刻都是同一个版本的,不存在介于老版本与新版本之间的中间状态。
现在,我们又该如何来解决这个问题呢?
我们可以将浅拷贝替换为深拷贝。newKeywords不仅仅复制currentKeywords的索引,还把SearchWord对象也复制一份出来,这样newKeywords和currentKeywords就指向不同的SearchWord对象,也就不存在更新newKeywords的数据会导致currentKeywords的数据也被更新的问题了。
那如何实现深拷贝呢?总结一下的话,有下面两种方法。
第一种方法:递归拷贝对象、对象的引用对象以及引用对象的引用对象……直到要拷贝的对象只包含基本数据类型数据,没有引用对象为止。根据这个思路对之前的代码进行重构。重构之后的代码如下所示:
public class Demo {
private HashMap<String, SearchWord> currentKeywords=new HashMap<>();
private long lastUpdateTime = -1;
public void refresh() {
// Deep copy
HashMap<String, SearchWord> newKeywords = new HashMap<>();
for (HashMap.Entry<String, SearchWord> e : currentKeywords.entrySet()) {
SearchWord searchWord = e.getValue();
SearchWord newSearchWord = new SearchWord(
searchWord.getKeyword(), searchWord.getCount(), searchWord.getLastUpdateTime());
newKeywords.put(e.getKey(), newSearchWord);
}
// 从数据库中取出更新时间>lastUpdateTime的数据,放入到newKeywords中
List<SearchWord> toBeUpdatedSearchWords = getSearchWords(lastUpdateTime);
long maxNewUpdatedTime = lastUpdateTime;
for (SearchWord searchWord : toBeUpdatedSearchWords) {
if (searchWord.getLastUpdateTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = searchWord.getLastUpdateTime();
}
if (newKeywords.containsKey(searchWord.getKeyword())) {
SearchWord oldSearchWord = newKeywords.get(searchWord.getKeyword());
oldSearchWord.setCount(searchWord.getCount());
oldSearchWord.setLastUpdateTime(searchWord.getLastUpdateTime());
} else {
newKeywords.put(searchWord.getKeyword(), searchWord);
}
}
lastUpdateTime = maxNewUpdatedTime;
currentKeywords = newKeywords;
}
private List<SearchWord> getSearchWords(long lastUpdateTime) {
// TODO: 从数据库中取出更新时间>lastUpdateTime的数据
return null;
}
}
第二种方法:先将对象序列化,然后再反序列化成新的对象。具体的示例代码如下所示:
public Object deepCopy(Object object) {
ByteArrayOutputStream bo = new ByteArrayOutputStream();
ObjectOutputStream oo = new ObjectOutputStream(bo);
oo.writeObject(object);
ByteArrayInputStream bi = new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi = new ObjectInputStream(bi);
return oi.readObject();
}
刚刚的两种实现方法,不管采用哪种,深拷贝都要比浅拷贝耗时、耗内存空间。针对我们这个应用场景,有没有更快、更省内存的实现方式呢?
我们可以先采用浅拷贝的方式创建newKeywords。对于需要更新的SearchWord对象,我们再使用深度拷贝的方式创建一份新的对象,替换newKeywords中的老对象。毕竟需要更新的数据是很少的。这种方式即利用了浅拷贝节省时间、空间的优点,又能保证currentKeywords中的中数据都是老版本的数据。具体的代码实现如下所示。这也是标题中讲到的,在我们这个应用场景下,最快速clone散列表的方式。
public class Demo {
private HashMap<String, SearchWord> currentKeywords=new HashMap<>();
private long lastUpdateTime = -1;
public void refresh() {
// Shallow copy
HashMap<String, SearchWord> newKeywords = (HashMap<String, SearchWord>) currentKeywords.clone();
// 从数据库中取出更新时间>lastUpdateTime的数据,放入到newKeywords中
List<SearchWord> toBeUpdatedSearchWords = getSearchWords(lastUpdateTime);
long maxNewUpdatedTime = lastUpdateTime;
for (SearchWord searchWord : toBeUpdatedSearchWords) {
if (searchWord.getLastUpdateTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = searchWord.getLastUpdateTime();
}
if (newKeywords.containsKey(searchWord.getKeyword())) {
newKeywords.remove(searchWord.getKeyword());
}
newKeywords.put(searchWord.getKeyword(), searchWord);
}
lastUpdateTime = maxNewUpdatedTime;
currentKeywords = newKeywords;
}
private List<SearchWord> getSearchWords(long lastUpdateTime) {
// TODO: 从数据库中取出更新时间>lastUpdateTime的数据
return null;
}
}
五、设计模式与范式:结构型
代理模式
代理模式的原理解析
代理模式(Proxy Design Pattern)的原理和代码实现都不难掌握。它在不改变原始类(或叫被代理类)代码的情况下,通过引入代理类来给原始类附加功能。
我们以之前讲的性能计数器作为例子。当时我们开发了一个MetricsCollector类,用来收集接口请求的原始数据,比如访问时间、处理时长等。在业务系统中,我们采用如下方式来使用这个MetricsCollector类:
public class UserController {
//...省略其他属性和方法...
private MetricsCollector metricsCollector; // 依赖注入
public UserVo login(String telephone, String password) {
long startTimestamp = System.currentTimeMillis();
// ... 省略login逻辑...
long endTimeStamp = System.currentTimeMillis();
long responseTime = endTimeStamp - startTimestamp;
RequestInfo requestInfo = new RequestInfo("login", responseTime, startTimestamp);
metricsCollector.recordRequest(requestInfo);
//...返回UserVo数据...
}
public UserVo register(String telephone, String password) {
long startTimestamp = System.currentTimeMillis();
// ... 省略register逻辑...
long endTimeStamp = System.currentTimeMillis();
long responseTime = endTimeStamp - startTimestamp;
RequestInfo requestInfo = new RequestInfo("register", responseTime, startTimestamp);
metricsCollector.recordRequest(requestInfo);
//...返回UserVo数据...
}
}
很明显,上面的写法有两个问题。第一,性能计数器框架代码侵入到业务代码中,跟业务代码高度耦合。如果未来需要替换这个框架,那替换的成本会比较大。第二,收集接口请求的代码跟业务代码无关,本就不应该放到一个类中。业务类最好职责更加单一,只聚焦业务处理。
为了将框架代码和业务代码解耦,代理模式就派上用场了。代理类UserControllerProxy和原始类UserController实现相同的接口IUserController。UserController类只负责业务功能。代理类UserControllerProxy负责在业务代码执行前后附加其他逻辑代码,并通过委托的方式调用原始类来执行业务代码。具体的代码实现如下所示:
public interface IUserController {
UserVo login(String telephone, String password);
UserVo register(String telephone, String password);
}
public class UserController implements IUserController {
//...省略其他属性和方法...
@Override
public UserVo login(String telephone, String password) {
//...省略login逻辑...
//...返回UserVo数据...
}
@Override
public UserVo register(String telephone, String password) {
//...省略register逻辑...
//...返回UserVo数据...
}
}
public class UserControllerProxy implements IUserController {
private MetricsCollector metricsCollector;
private UserController userController;
public UserControllerProxy(UserController userController) {
this.userController = userController;
this.metricsCollector = new MetricsCollector();
}
@Override
public UserVo login(String telephone, String password) {
long startTimestamp = System.currentTimeMillis();
// 委托
UserVo userVo = userController.login(telephone, password);
long endTimeStamp = System.currentTimeMillis();
long responseTime = endTimeStamp - startTimestamp;
RequestInfo requestInfo = new RequestInfo("login", responseTime, startTimestamp);
metricsCollector.recordRequest(requestInfo);
return userVo;
}
@Override
public UserVo register(String telephone, String password) {
long startTimestamp = System.currentTimeMillis();
UserVo userVo = userController.register(telephone, password);
long endTimeStamp = System.currentTimeMillis();
long responseTime = endTimeStamp - startTimestamp;
RequestInfo requestInfo = new RequestInfo("register", responseTime, startTimestamp);
metricsCollector.recordRequest(requestInfo);
return userVo;
}
}
//UserControllerProxy使用举例
//因为原始类和代理类实现相同的接口,是基于接口而非实现编程
//将UserController类对象替换为UserControllerProxy类对象,不需要改动太多代码
IUserController userController = new UserControllerProxy(new UserController());
参照基于接口而非实现编程的设计思想,将原始类对象替换为代理类对象的时候,为了让代码改动尽量少,在刚刚的代理模式的代码实现中,代理类和原始类需要实现相同的接口。但是,如果原始类并没有定义接口,并且原始类代码并不是我们开发维护的(比如它来自一个第三方的类库),我们也没办法直接修改原始类,给它重新定义一个接口。在这种情况下,我们该如何实现代理模式呢?
对于这种外部类的扩展,我们一般都是采用继承的方式。这里也不例外。我们让代理类继承原始类,然后扩展附加功能。
public class UserControllerProxy extends UserController {
private MetricsCollector metricsCollector;
public UserControllerProxy() {
this.metricsCollector = new MetricsCollector();
}
public UserVo login(String telephone, String password) {
long startTimestamp = System.currentTimeMillis();
UserVo userVo = super.login(telephone, password);
long endTimeStamp = System.currentTimeMillis();
long responseTime = endTimeStamp - startTimestamp;
RequestInfo requestInfo = new RequestInfo("login", responseTime, startTimestamp);
metricsCollector.recordRequest(requestInfo);
return userVo;
}
public UserVo register(String telephone, String password) {
long startTimestamp = System.currentTimeMillis();
UserVo userVo = super.register(telephone, password);
long endTimeStamp = System.currentTimeMillis();
long responseTime = endTimeStamp - startTimestamp;
RequestInfo requestInfo = new RequestInfo("register", responseTime, startTimestamp);
metricsCollector.recordRequest(requestInfo);
return userVo;
}
}
//UserControllerProxy使用举例
UserController userController = new UserControllerProxy();
动态代理的原理解析
不过,刚刚的代码实现还是有点问题。一方面,我们需要在代理类中,将原始类中的所有的方法,都重新实现一遍,并且为每个方法都附加相似的代码逻辑。另一方面,如果要添加的附加功能的类有不止一个,我们需要针对每个类都创建一个代理类。
如果有50个要添加附加功能的原始类,那我们就要创建50个对应的代理类。这会导致项目中类的个数成倍增加,增加了代码维护成本。并且,每个代理类中的代码都有点像模板式的“重复”代码,也增加了不必要的开发成本。那这个问题怎么解决呢?
我们可以使用动态代理来解决这个问题。所谓动态代理(Dynamic Proxy),就是我们不事先为每个原始类编写代理类,而是在运行的时候,动态地创建原始类对应的代理类,然后在系统中用代理类替换掉原始类。那如何实现动态代理呢?
如果你熟悉的是Java语言,实现动态代理就是件很简单的事情。因为Java语言本身就已经提供了动态代理的语法(实际上,动态代理底层依赖的就是Java的反射语法)。我们来看一下,如何用Java的动态代理来实现刚刚的功能。具体的代码如下所示。其中,MetricsCollectorProxy作为一个动态代理类,动态地给每个需要收集接口请求信息的类创建代理类。
public class MetricsCollectorProxy {
private MetricsCollector metricsCollector;
public MetricsCollectorProxy() {
this.metricsCollector = new MetricsCollector();
}
public Object createProxy(Object proxiedObject) {
Class<?>[] interfaces = proxiedObject.getClass().getInterfaces();
DynamicProxyHandler handler = new DynamicProxyHandler(proxiedObject);
return Proxy.newProxyInstance(proxiedObject.getClass().getClassLoader(), interfaces, handler);
}
private class DynamicProxyHandler implements InvocationHandler {
private Object proxiedObject;
public DynamicProxyHandler(Object proxiedObject) {
this.proxiedObject = proxiedObject;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
long startTimestamp = System.currentTimeMillis();
Object result = method.invoke(proxiedObject, args);
long endTimeStamp = System.currentTimeMillis();
long responseTime = endTimeStamp - startTimestamp;
String apiName = proxiedObject.getClass().getName() + ":" + method.getName();
RequestInfo requestInfo = new RequestInfo(apiName, responseTime, startTimestamp);
metricsCollector.recordRequest(requestInfo);
return result;
}
}
}
//MetricsCollectorProxy使用举例
MetricsCollectorProxy proxy = new MetricsCollectorProxy();
IUserController userController = (IUserController) proxy.createProxy(new UserController());
实际上,Spring AOP底层的实现原理就是基于动态代理。用户配置好需要给哪些类创建代理,并定义好在执行原始类的业务代码前后执行哪些附加功能。Spring为这些类创建动态代理对象,并在JVM中替代原始类对象。原本在代码中执行的原始类的方法,被换作执行代理类的方法,也就实现了给原始类添加附加功能的目的。
代理模式的应用场景
1.业务系统的非功能性需求开发
代理模式最常用的一个应用场景就是,在业务系统中开发一些非功能性需求,比如:监控、统计、鉴权、限流、事务、幂等、日志。我们将这些附加功能与业务功能解耦,放到代理类中统一处理,让程序员只需要关注业务方面的开发。
2.代理模式在RPC、缓存中的应用
实际上,RPC框架也可以看作一种代理模式,GoF的《设计模式》一书中把它称作远程代理。通过远程代理,将网络通信、数据编解码等细节隐藏起来。客户端在使用RPC服务的时候,就像使用本地函数一样,无需了解跟服务器交互的细节。除此之外,RPC服务的开发者也只需要开发业务逻辑,就像开发本地使用的函数一样,不需要关注跟客户端的交互细节。
**我们再来看代理模式在缓存中的应用。**假设我们要开发一个接口请求的缓存功能,对于某些接口请求,如果入参相同,在设定的过期时间内,直接返回缓存结果,而不用重新进行逻辑处理。比如,针对获取用户个人信息的需求,我们可以开发两个接口,一个支持缓存,一个支持实时查询。对于需要实时数据的需求,我们让其调用实时查询接口,对于不需要实时数据的需求,我们让其调用支持缓存的接口。那如何来实现接口请求的缓存功能呢?
最简单的实现方法就是刚刚我们讲到的,给每个需要支持缓存的查询需求都开发两个不同的接口,一个支持缓存,一个支持实时查询。但是,这样做显然增加了开发成本,而且会让代码看起来非常臃肿(接口个数成倍增加),也不方便缓存接口的集中管理(增加、删除缓存接口)、集中配置(比如配置每个接口缓存过期时间)。
针对这些问题,代理模式就能派上用场了,确切地说,应该是动态代理。如果是基于Spring框架来开发的话,那就可以在AOP切面中完成接口缓存的功能。在应用启动的时候,我们从配置文件中加载需要支持缓存的接口,以及相应的缓存策略(比如过期时间)等。当请求到来的时候,我们在AOP切面中拦截请求,如果请求中带有支持缓存的字段(比如http://…?..&cached=true),我们便从缓存(内存缓存或者Redis缓存等)中获取数据直接返回。
桥接模式
个人认为课程的这部分解释得不是很好。可以参考博文 https://refactoringguru.cn/design-patterns/bridge
桥接模式,也叫作桥梁模式,英文是Bridge Design Pattern。
桥接模式的原理解析
这个模式有两种不同的理解方式。
当然,这其中“最纯正”的理解方式,当属GoF的《设计模式》一书中对桥接模式的定义。毕竟,这23种经典的设计模式,最初就是由这本书总结出来的。在GoF的《设计模式》一书中,桥接模式是这么定义的:“Decouple an abstraction from its implementation so that the two can vary independently。”翻译成中文就是:“将抽象和实现解耦,让它们可以独立变化。”
关于桥接模式,很多书籍、资料中,还有另外一种理解方式:“一个类存在两个(或多个)独立变化的维度,我们通过组合的方式,让这两个(或多个)维度可以独立进行扩展。”通过组合关系来替代继承关系,避免继承层次的指数级爆炸。这种理解方式非常类似于,我们之前讲过的“组合优于继承”设计原则,所以,这里我就不多解释了。我们重点看下GoF的理解方式。
GoF给出的定义非常的简短,单凭这一句话,估计没几个人能看懂是什么意思。所以,我们通过JDBC驱动的例子来解释一下。JDBC驱动是桥接模式的经典应用。我们先来看一下,如何利用JDBC驱动来查询数据库。具体的代码如下所示:
Class.forName("com.mysql.jdbc.Driver");//加载及注册JDBC驱动程序
String url = "jdbc:mysql://localhost:3306/sample_db?user=root&password=your_password";
Connection con = DriverManager.getConnection(url);
Statement stmt = con.createStatement();
String query = "select * from test";
ResultSet rs=stmt.executeQuery(query);
while(rs.next()) {
rs.getString(1);
rs.getInt(2);
}
如果我们想要把MySQL数据库换成Oracle数据库,只需要把第一行代码中的com.mysql.jdbc.Driver换成oracle.jdbc.driver.OracleDriver就可以了。当然,也有更灵活的实现方式,我们可以把需要加载的Driver类写到配置文件中,当程序启动的时候,自动从配置文件中加载,这样在切换数据库的时候,我们都不需要修改代码,只需要修改配置文件就可以了。
不管是改代码还是改配置,在项目中,从一个数据库切换到另一种数据库,都只需要改动很少的代码,或者完全不需要改动代码,那如此优雅的数据库切换是如何实现的呢?
源码之下无秘密。要弄清楚这个问题,我们先从com.mysql.jdbc.Driver这个类的代码看起。我摘抄了部分相关代码,放到了这里,你可以看一下。
package com.mysql.jdbc;
import java.sql.SQLException;
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
/**
* Construct a new driver and register it with DriverManager
* @throws SQLException if a database error occurs.
*/
public Driver() throws SQLException {
// Required for Class.forName().newInstance()
}
}
结合com.mysql.jdbc.Driver的代码实现,我们可以发现,当执行Class.forName(“com.mysql.jdbc.Driver”)这条语句的时候,实际上是做了两件事情。第一件事情是要求JVM查找并加载指定的Driver类,第二件事情是执行该类的静态代码,也就是将MySQL Driver注册到DriverManager类中。
现在,我们再来看一下,DriverManager类是干什么用的。具体的代码如下所示。当我们把具体的Driver实现类(比如,com.mysql.jdbc.Driver)注册到DriverManager之后,后续所有对JDBC接口的调用,都会委派到对具体的Driver实现类来执行。而Driver实现类都实现了相同的接口(java.sql.Driver ),这也是可以灵活切换Driver的原因。
public class DriverManager {
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<DriverInfo>();
//...
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
//...
public static synchronized void registerDriver(java.sql.Driver driver) throws SQLException {
if (driver != null) {
registeredDrivers.addIfAbsent(new DriverInfo(driver));
} else {
throw new NullPointerException();
}
}
public static Connection getConnection(String url, String user, String password) throws SQLException {
java.util.Properties info = new java.util.Properties();
if (user != null) {
info.put("user", user);
}
if (password != null) {
info.put("password", password);
}
return (getConnection(url, info, Reflection.getCallerClass()));
}
//...
}
桥接模式的定义是“将抽象和实现解耦,让它们可以独立变化”。那弄懂定义中“抽象”和“实现”两个概念,就是理解桥接模式的关键。那在JDBC这个例子中,什么是“抽象”?什么是“实现”呢?
实际上,JDBC本身就相当于“抽象”。注意,这里所说的“抽象”,指的并非“抽象类”或“接口”,而是跟具体的数据库无关的、被抽象出来的一套“类库”。具体的Driver(比如,com.mysql.jdbc.Driver)就相当于“实现”。注意,这里所说的“实现”,也并非指“接口的实现类”,而是跟具体数据库相关的一套“类库”。JDBC和Driver独立开发,通过对象之间的组合关系,组装在一起。JDBC的所有逻辑操作,最终都委托给Driver来执行。
应用举例
我们讲过一个API接口监控告警的例子:根据不同的告警规则,触发不同类型的告警。告警支持多种通知渠道,包括:邮件、短信、微信、自动语音电话。通知的紧急程度有多种类型,包括:SEVERE(严重)、URGENCY(紧急)、NORMAL(普通)、TRIVIAL(无关紧要)。不同的紧急程度对应不同的通知渠道。比如,SERVE(严重)级别的消息会通过“自动语音电话”告知相关人员。
在当时的代码实现中,关于发送告警信息那部分代码,我们只给出了粗略的设计,现在我们来一块实现一下。我们先来看最简单、最直接的一种实现方式。代码如下所示:
public enum NotificationEmergencyLevel {
SEVERE, URGENCY, NORMAL, TRIVIAL
}
public class Notification {
private List<String> emailAddresses;
private List<String> telephones;
private List<String> wechatIds;
public Notification() {}
public void setEmailAddress(List<String> emailAddress) {
this.emailAddresses = emailAddress;
}
public void setTelephones(List<String> telephones) {
this.telephones = telephones;
}
public void setWechatIds(List<String> wechatIds) {
this.wechatIds = wechatIds;
}
public void notify(NotificationEmergencyLevel level, String message) {
if (level.equals(NotificationEmergencyLevel.SEVERE)) {
//...自动语音电话
} else if (level.equals(NotificationEmergencyLevel.URGENCY)) {
//...发微信
} else if (level.equals(NotificationEmergencyLevel.NORMAL)) {
//...发邮件
} else if (level.equals(NotificationEmergencyLevel.TRIVIAL)) {
//...发邮件
}
}
}
//在API监控告警的例子中,我们如下方式来使用Notification类:
public class ErrorAlertHandler extends AlertHandler {
public ErrorAlertHandler(AlertRule rule, Notification notification){
super(rule, notification);
}
@Override
public void check(ApiStatInfo apiStatInfo) {
if (apiStatInfo.getErrorCount() > rule.getMatchedRule(apiStatInfo.getApi()).getMaxErrorCount()) {
notification.notify(NotificationEmergencyLevel.SEVERE, "...");
}
}
}
Notification类的代码实现有一个最明显的问题,那就是有很多if-else分支逻辑。实际上,如果每个分支中的代码都不复杂,后期也没有无限膨胀的可能(增加更多if-else分支判断),那这样的设计问题并不大,没必要非得一定要摒弃if-else分支逻辑。
不过,Notification的代码显然不符合这个条件。因为每个if-else分支中的代码逻辑都比较复杂,发送通知的所有逻辑都扎堆在Notification类中。我们知道,类的代码越多,就越难读懂,越难修改,维护的成本也就越高。很多设计模式都是试图将庞大的类拆分成更细小的类,然后再通过某种更合理的结构组装在一起。
针对Notification的代码,我们将不同渠道的发送逻辑剥离出来,形成独立的消息发送类(MsgSender相关类)。其中,Notification类相当于抽象,MsgSender类相当于实现,两者可以独立开发,通过组合关系(也就是桥梁)任意组合在一起。所谓任意组合的意思就是,不同紧急程度的消息和发送渠道之间的对应关系,不是在代码中固定写死的,我们可以动态地去指定(比如,通过读取配置来获取对应关系)。
按照这个设计思路,我们对代码进行重构。重构之后的代码如下所示:
public interface MsgSender {
void send(String message);
}
public class TelephoneMsgSender implements MsgSender {
private List<String> telephones;
public TelephoneMsgSender(List<String> telephones) {
this.telephones = telephones;
}
@Override
public void send(String message) {
//...
}
}
public class EmailMsgSender implements MsgSender {
// 与TelephoneMsgSender代码结构类似,所以省略...
}
public class WechatMsgSender implements MsgSender {
// 与TelephoneMsgSender代码结构类似,所以省略...
}
public abstract class Notification {
protected MsgSender msgSender;
public Notification(MsgSender msgSender) {
this.msgSender = msgSender;
}
public abstract void notify(String message);
}
public class SevereNotification extends Notification {
public SevereNotification(MsgSender msgSender) {
super(msgSender);
}
@Override
public void notify(String message) {
msgSender.send(message);
}
}
public class UrgencyNotification extends Notification {
// 与SevereNotification代码结构类似,所以省略...
}
public class NormalNotification extends Notification {
// 与SevereNotification代码结构类似,所以省略...
}
public class TrivialNotification extends Notification {
// 与SevereNotification代码结构类似,所以省略...
}
装饰器模式
Java IO类的“奇怪”用法
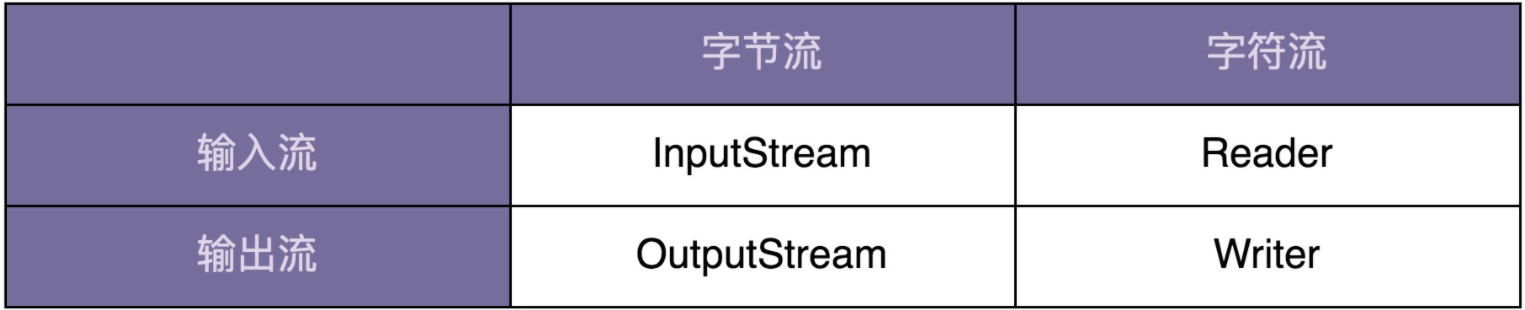
Java IO类库非常庞大和复杂,有几十个类,负责IO数据的读取和写入。如果对Java IO类做一下分类,我们可以从下面两个维度将它划分为四类。具体如下所示:
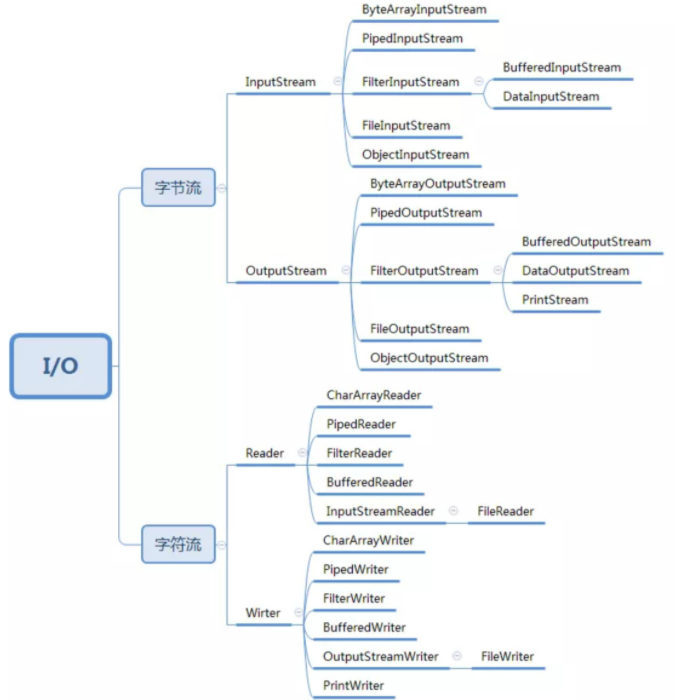
针对不同的读取和写入场景,Java IO又在这四个父类基础之上,扩展出了很多子类。具体如下所示:
比如下面这样一段代码。我们打开文件test.txt,从中读取数据。其中,InputStream是一个抽象类,FileInputStream是专门用来读取文件流的子类。BufferedInputStream是一个支持带缓存功能的数据读取类,可以提高数据读取的效率。
InputStream in = new FileInputStream("/user/wangzheng/test.txt");
InputStream bin = new BufferedInputStream(in);
byte[] data = new byte[128];
while (bin.read(data) != -1) {
//...
}
初看上面的代码,我们会觉得Java IO的用法比较麻烦,需要先创建一个FileInputStream对象,然后再传递给BufferedInputStream对象来使用。我在想,Java IO为什么不设计一个继承FileInputStream并且支持缓存的BufferedFileInputStream类呢?这样我们就可以像下面的代码中这样,直接创建一个BufferedFileInputStream类对象,打开文件读取数据,用起来岂不是更加简单?
InputStream bin = new BufferedFileInputStream("/user/wangzheng/test.txt");
byte[] data = new byte[128];
while (bin.read(data) != -1) {
//...
}
基于继承的设计方案
如果InputStream只有一个子类FileInputStream的话,那我们在FileInputStream基础之上,再设计一个孙子类BufferedFileInputStream,也算是可以接受的,毕竟继承结构还算简单。但实际上,继承InputStream的子类有很多。我们需要给每一个InputStream的子类,再继续派生支持缓存读取的子类。
除了支持缓存读取之外,如果我们还需要对功能进行其他方面的增强,比如下面的DataInputStream类,支持按照基本数据类型(int、boolean、long等)来读取数据。
FileInputStream in = new FileInputStream("/user/wangzheng/test.txt");
DataInputStream din = new DataInputStream(in);
int data = din.readInt();
在这种情况下,如果我们继续按照继承的方式来实现的话,就需要再继续派生出DataFileInputStream、DataPipedInputStream等类。如果我们还需要既支持缓存、又支持按照基本类型读取数据的类,那就要再继续派生出BufferedDataFileInputStream、BufferedDataPipedInputStream等n多类。这还只是附加了两个增强功能,如果我们需要附加更多的增强功能,那就会导致组合爆炸,类继承结构变得无比复杂,代码既不好扩展,也不好维护。
基于装饰器模式的设计方案
针对刚刚的继承结构过于复杂的问题,我们可以通过将继承关系改为组合关系来解决。下面的代码展示了Java IO的这种设计思路。
public abstract class InputStream {
//...
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
public int read(byte b[], int off, int len) throws IOException {
//...
}
public long skip(long n) throws IOException {
//...
}
public int available() throws IOException {
return 0;
}
public void close() throws IOException {}
public synchronized void mark(int readlimit) {}
public synchronized void reset() throws IOException {
throw new IOException("mark/reset not supported");
}
public boolean markSupported() {
return false;
}
}
public class BufferedInputStream extends InputStream {
protected volatile InputStream in;
protected BufferedInputStream(InputStream in) {
this.in = in;
}
//...实现基于缓存的读数据接口...
}
public class DataInputStream extends InputStream {
protected volatile InputStream in;
protected DataInputStream(InputStream in) {
this.in = in;
}
//...实现读取基本类型数据的接口
}
从Java IO的设计来看,装饰器模式相对于简单的组合关系,还有两个比较特殊的地方。
**第一个比较特殊的地方是:装饰器类和原始类继承同样的父类,这样我们可以对原始类“嵌套”多个装饰器类。**比如,下面这样一段代码,我们对FileInputStream嵌套了两个装饰器类:BufferedInputStream和DataInputStream,让它既支持缓存读取,又支持按照基本数据类型来读取数据。
InputStream in = new FileInputStream("/user/wangzheng/test.txt");
InputStream bin = new BufferedInputStream(in);
DataInputStream din = new DataInputStream(bin);
int data = din.readInt();
**第二个比较特殊的地方是:装饰器类是对功能的增强,这也是装饰器模式应用场景的一个重要特点。**实际上,符合“组合关系”这种代码结构的设计模式有很多,比如之前讲过的代理模式、桥接模式,还有现在的装饰器模式。尽管它们的代码结构很相似,但是每种设计模式的意图是不同的。就拿比较相似的代理模式和装饰器模式来说吧,代理模式中,代理类附加的是跟原始类无关的功能,而在装饰器模式中,装饰器类附加的是跟原始类相关的增强功能。
// 代理模式的代码结构(下面的接口也可以替换成抽象类)
public interface IA {
void f();
}
public class A impelements IA {
public void f() { //... }
}
public class AProxy implements IA {
private IA a;
public AProxy(IA a) {
this.a = a;
}
public void f() {
// 新添加的代理逻辑
a.f();
// 新添加的代理逻辑
}
}
// 装饰器模式的代码结构(下面的接口也可以替换成抽象类)
public interface IA {
void f();
}
public class A implements IA {
public void f() { //... }
}
public class ADecorator implements IA {
private IA a;
public ADecorator(IA a) {
this.a = a;
}
public void f() {
// 功能增强代码
a.f();
// 功能增强代码
}
}
实际上,如果去查看JDK的源码,你会发现,BufferedInputStream、DataInputStream并非继承自InputStream,而是另外一个叫FilterInputStream的类。那这又是出于什么样的设计意图,才引入这样一个类呢?
我们再重新来看一下BufferedInputStream类的代码。InputStream是一个抽象类而非接口,而且它的大部分函数(比如read()、available())都有默认实现,按理来说,我们只需要在BufferedInputStream类中重新实现那些需要增加缓存功能的函数就可以了,其他函数继承InputStream的默认实现。但实际上,这样做是行不通的。
对于即便是不需要增加缓存功能的函数来说,BufferedInputStream还是必须把它重新实现一遍,简单包裹对InputStream对象的函数调用。具体的代码示例如下所示。如果不重新实现,那BufferedInputStream类就无法将最终读取数据的任务,委托给传递进来的InputStream对象来完成。这一部分稍微有点不好理解,你自己多思考一下。
public class BufferedInputStream extends InputStream {
protected volatile InputStream in;
protected BufferedInputStream(InputStream in) {
this.in = in;
}
// f()函数不需要增强,只是重新调用一下InputStream in对象的f()
public void f() {
in.f();
}
}
实际上,DataInputStream也存在跟BufferedInputStream同样的问题。为了避免代码重复,Java IO抽象出了一个装饰器父类FilterInputStream,代码实现如下所示。InputStream的所有的装饰器类(BufferedInputStream、DataInputStream)都继承自这个装饰器父类。这样,装饰器类只需要实现它需要增强的方法就可以了,其他方法继承装饰器父类的默认实现。
public class FilterInputStream extends InputStream {
protected volatile InputStream in;
protected FilterInputStream(InputStream in) {
this.in = in;
}
public int read() throws IOException {
return in.read();
}
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
public int read(byte b[], int off, int len) throws IOException {
return in.read(b, off, len);
}
public long skip(long n) throws IOException {
return in.skip(n);
}
public int available() throws IOException {
return in.available();
}
public void close() throws IOException {
in.close();
}
public synchronized void mark(int readlimit) {
in.mark(readlimit);
}
public synchronized void reset() throws IOException {
in.reset();
}
public boolean markSupported() {
return in.markSupportezd();
}
}
适配器模式
原理与实现
适配器模式Adapter Design Pattern。顾名思义就是用来做适配的,它将不兼容的接口转换为可兼容的接口,让原本由于接口不兼容而不能一起工作的类可以一起工作。对于这个模式,有一个经常被拿来解释它的例子,就是USB转接头充当适配器,把两种不兼容的接口,通过转接变得可以一起工作。
适配器模式有两种实现方式:类适配器和对象适配器。其中,类适配器使用继承关系来实现,对象适配器使用组合关系来实现。具体的代码实现如下所示。其中,ITarget表示要转化成的接口定义。Adaptee是一组不兼容ITarget接口定义的接口,Adaptor将Adaptee转化成一组符合ITarget接口定义的接口。
// 类适配器: 基于继承
public interface ITarget {
void f1();
void f2();
void fc();
}
public class Adaptee {
public void fa() { //... }
public void fb() { //... }
public void fc() { //... }
}
public class Adaptor extends Adaptee implements ITarget {
public void f1() {
super.fa();
}
public void f2() {
//...重新实现f2()...
}
// 这里fc()不需要实现,直接继承自Adaptee,这是跟对象适配器最大的不同点
}
// 对象适配器:基于组合
public interface ITarget {
void f1();
void f2();
void fc();
}
public class Adaptee {
public void fa() { //... }
public void fb() { //... }
public void fc() { //... }
}
public class Adaptor implements ITarget {
private Adaptee adaptee;
public Adaptor(Adaptee adaptee) {
this.adaptee = adaptee;
}
public void f1() {
adaptee.fa(); //委托给Adaptee
}
public void f2() {
//...重新实现f2()...
}
public void fc() {
adaptee.fc();
}
}
针对这两种实现方式,在实际的开发中,到底该如何选择使用哪一种呢?判断的标准主要有两个,一个是Adaptee接口的个数,另一个是Adaptee和ITarget的契合程度。
- 如果Adaptee接口并不多,那两种实现方式都可以。
- 如果Adaptee接口很多,而且Adaptee和ITarget接口定义大部分都相同,那我们推荐使用类适配器,因为Adaptor复用父类Adaptee的接口,比起对象适配器的实现方式,Adaptor的代码量要少一些。
- 如果Adaptee接口很多,而且Adaptee和ITarget接口定义大部分都不相同,那我们推荐使用对象适配器,因为组合结构相对于继承更加灵活。
应用场景
一般来说,适配器模式可以看作一种“补偿模式”,用来补救设计上的缺陷。应用这种模式算是“无奈之举”。如果在设计初期,我们就能协调规避接口不兼容的问题,那这种模式就没有应用的机会了。
前面我们反复提到,适配器模式的应用场景是“接口不兼容”。那在实际的开发中,什么情况下才会出现接口不兼容呢?
- 封装有缺陷的接口设计
假设我们依赖的外部系统在接口设计方面有缺陷(比如包含大量静态方法),引入之后会影响到我们自身代码的可测试性。为了隔离设计上的缺陷,我们希望对外部系统提供的接口进行二次封装,抽象出更好的接口设计,这个时候就可以使用适配器模式了。
举个例子:
public class CD { //这个类来自外部sdk,我们无权修改它的代码
//...
public static void staticFunction1() { //... }
public void uglyNamingFunction2() { //... }
public void tooManyParamsFunction3(int paramA, int paramB, ...) { //... }
public void lowPerformanceFunction4() { //... }
}
// 使用适配器模式进行重构
public class ITarget {
void function1();
void function2();
void fucntion3(ParamsWrapperDefinition paramsWrapper);
void function4();
//...
}
// 注意:适配器类的命名不一定非得末尾带Adaptor
public class CDAdaptor extends CD implements ITarget {
//...
public void function1() {
super.staticFunction1();
}
public void function2() {
super.uglyNamingFucntion2();
}
public void function3(ParamsWrapperDefinition paramsWrapper) {
super.tooManyParamsFunction3(paramsWrapper.getParamA(), ...);
}
public void function4() {
//...reimplement it...
}
}
- 统一多个类的接口设计
某个功能的实现依赖多个外部系统(或者说类)。通过适配器模式,将它们的接口适配为统一的接口定义,然后我们就可以使用多态的特性来复用代码逻辑。具体我还是举个例子来解释一下。
假设我们的系统要对用户输入的文本内容做敏感词过滤,为了提高过滤的召回率,我们引入了多款第三方敏感词过滤系统,依次对用户输入的内容进行过滤,过滤掉尽可能多的敏感词。但是,每个系统提供的过滤接口都是不同的。这就意味着我们没法复用一套逻辑来调用各个系统。这个时候,我们就可以使用适配器模式,将所有系统的接口适配为统一的接口定义,这样我们可以复用调用敏感词过滤的代码。
你可以配合着下面的代码示例,来理解我刚才举的这个例子。
public class ASensitiveWordsFilter { // A敏感词过滤系统提供的接口
//text是原始文本,函数输出用***替换敏感词之后的文本
public String filterSexyWords(String text) {
// ...
}
public String filterPoliticalWords(String text) {
// ...
}
}
public class BSensitiveWordsFilter { // B敏感词过滤系统提供的接口
public String filter(String text) {
//...
}
}
public class CSensitiveWordsFilter { // C敏感词过滤系统提供的接口
public String filter(String text, String mask) {
//...
}
}
// 未使用适配器模式之前的代码:代码的可测试性、扩展性不好
public class RiskManagement {
private ASensitiveWordsFilter aFilter = new ASensitiveWordsFilter();
private BSensitiveWordsFilter bFilter = new BSensitiveWordsFilter();
private CSensitiveWordsFilter cFilter = new CSensitiveWordsFilter();
public String filterSensitiveWords(String text) {
String maskedText = aFilter.filterSexyWords(text);
maskedText = aFilter.filterPoliticalWords(maskedText);
maskedText = bFilter.filter(maskedText);
maskedText = cFilter.filter(maskedText, "***");
return maskedText;
}
}
// 使用适配器模式进行改造
public interface ISensitiveWordsFilter { // 统一接口定义
String filter(String text);
}
public class ASensitiveWordsFilterAdaptor implements ISensitiveWordsFilter {
private ASensitiveWordsFilter aFilter;
public String filter(String text) {
String maskedText = aFilter.filterSexyWords(text);
maskedText = aFilter.filterPoliticalWords(maskedText);
return maskedText;
}
}
//...省略BSensitiveWordsFilterAdaptor、CSensitiveWordsFilterAdaptor...
// 扩展性更好,更加符合开闭原则,如果添加一个新的敏感词过滤系统,
// 这个类完全不需要改动;而且基于接口而非实现编程,代码的可测试性更好。
public class RiskManagement {
private List<ISensitiveWordsFilter> filters = new ArrayList<>();
public void addSensitiveWordsFilter(ISensitiveWordsFilter filter) {
filters.add(filter);
}
public String filterSensitiveWords(String text) {
String maskedText = text;
for (ISensitiveWordsFilter filter : filters) {
maskedText = filter.filter(maskedText);
}
return maskedText;
}
}
- 替换依赖的外部系统
当我们把项目中依赖的一个外部系统替换为另一个外部系统的时候,利用适配器模式,可以减少对代码的改动。具体的代码示例如下所示:
// 外部系统A
public interface IA {
//...
void fa();
}
public class A implements IA {
//...
public void fa() { //... }
}
// 在我们的项目中,外部系统A的使用示例
public class Demo {
private IA a;
public Demo(IA a) {
this.a = a;
}
//...
}
Demo d = new Demo(new A());
// 将外部系统A替换成外部系统B
public class BAdaptor implemnts IA {
private B b;
public BAdaptor(B b) {
this.b= b;
}
public void fa() {
//...
b.fb();
}
}
// 借助BAdaptor,Demo的代码中,调用IA接口的地方都无需改动,
// 只需要将BAdaptor如下注入到Demo即可。
Demo d = new Demo(new BAdaptor(new B()));
- 兼容老版本接口
在做版本升级的时候,对于一些要废弃的接口,我们不直接将其删除,而是暂时保留,并且标注为deprecated,并将内部实现逻辑委托为新的接口实现。这样做的好处是,让使用它的项目有个过渡期,而不是强制进行代码修改。这也可以粗略地看作适配器模式的一个应用场景。同样,我还是通过一个例子,来进一步解释一下。
JDK1.0中包含一个遍历集合容器的类Enumeration。JDK2.0对这个类进行了重构,将它改名为Iterator类,并且对它的代码实现做了优化。但是考虑到如果将Enumeration直接从JDK2.0中删除,那使用JDK1.0的项目如果切换到JDK2.0,代码就会编译不通过。为了避免这种情况的发生,我们必须把项目中所有使用到Enumeration的地方,都修改为使用Iterator才行。
单独一个项目做Enumeration到Iterator的替换,勉强还能接受。但是,使用Java开发的项目太多了,一次JDK的升级,导致所有的项目不做代码修改就会编译报错,这显然是不合理的。这就是我们经常所说的不兼容升级。为了做到兼容使用低版本JDK的老代码,我们可以暂时保留Enumeration类,并将其实现替换为直接调用Itertor。代码示例如下所示:
public class Collections {
public static Emueration emumeration(final Collection c) {
return new Enumeration() {
Iterator i = c.iterator();
public boolean hasMoreElments() {
return i.hashNext();
}
public Object nextElement() {
return i.next():
}
}
}
}
- 适配不同格式的数据
前面我们讲到,适配器模式主要用于接口的适配,实际上,它还可以用在不同格式的数据之间的适配。比如,把从不同征信系统拉取的不同格式的征信数据,统一为相同的格式,以方便存储和使用。再比如,Java中的Arrays.asList()也可以看作一种数据适配器,将数组类型的数据转化为集合容器类型。
List<String> stooges = Arrays.asList("Larry", "Moe", "Curly");
剖析适配器模式在Java日志中的应用
Java中有很多日志框架,在项目开发中,我们常常用它们来打印日志信息。其中,比较常用的有log4j、logback,以及JDK提供的JUL(java.util.logging)和Apache的JCL(Jakarta Commons Logging)等。
大部分日志框架都提供了相似的功能,比如按照不同级别(debug、info、warn、erro……)打印日志等,但它们却并没有实现统一的接口。这主要可能是历史的原因,它不像JDBC那样,一开始就制定了数据库操作的接口规范。
如果我们只是开发一个自己用的项目,那用什么日志框架都可以,log4j、logback随便选一个就好。但是,如果我们开发的是一个集成到其他系统的组件、框架、类库等,那日志框架的选择就没那么随意了。
比如,项目中用到的某个组件使用log4j来打印日志,而我们项目本身使用的是logback。将组件引入到项目之后,我们的项目就相当于有了两套日志打印框架。每种日志框架都有自己特有的配置方式。所以,我们要针对每种日志框架编写不同的配置文件(比如,日志存储的文件地址、打印日志的格式)。如果引入多个组件,每个组件使用的日志框架都不一样,那日志本身的管理工作就变得非常复杂。所以,为了解决这个问题,我们需要统一日志打印框架。
如果你是做Java开发的,那Slf4j这个_x0008_日志框架你肯定不陌生,它相当于JDBC规范,提供了一套打印日志的统一接口规范。不过,它只定义了接口,并没有提供具体的实现,需要配合其他日志框架(log4j、logback……)来使用。
不仅如此,Slf4j的出现晚于JUL、JCL、log4j等日志框架,所以,这些日志框架也不可能牺牲掉版本兼容性,将接口改造成符合Slf4j接口规范。Slf4j也事先考虑到了这个问题,所以,它不仅仅提供了统一的接口定义,还提供了针对不同日志框架的适配器。对不同日志框架的接口进行二次封装,适配成统一的Slf4j接口定义。具体的代码示例如下所示:
// slf4j统一的接口定义
package org.slf4j;
public interface Logger {
public boolean isTraceEnabled();
public void trace(String msg);
public void trace(String format, Object arg);
public void trace(String format, Object arg1, Object arg2);
public void trace(String format, Object[] argArray);
public void trace(String msg, Throwable t);
public boolean isDebugEnabled();
public void debug(String msg);
public void debug(String format, Object arg);
public void debug(String format, Object arg1, Object arg2)
public void debug(String format, Object[] argArray)
public void debug(String msg, Throwable t);
//...省略info、warn、error等一堆接口
}
// log4j日志框架的适配器
// Log4jLoggerAdapter实现了LocationAwareLogger接口,
// 其中LocationAwareLogger继承自Logger接口,
// 也就相当于Log4jLoggerAdapter实现了Logger接口。
package org.slf4j.impl;
public final class Log4jLoggerAdapter extends MarkerIgnoringBase
implements LocationAwareLogger, Serializable {
final transient org.apache.log4j.Logger logger; // log4j
public boolean isDebugEnabled() {
return logger.isDebugEnabled();
}
public void debug(String msg) {
logger.log(FQCN, Level.DEBUG, msg, null);
}
public void debug(String format, Object arg) {
if (logger.isDebugEnabled()) {
FormattingTuple ft = MessageFormatter.format(format, arg);
logger.log(FQCN, Level.DEBUG, ft.getMessage(), ft.getThrowable());
}
}
public void debug(String format, Object arg1, Object arg2) {
if (logger.isDebugEnabled()) {
FormattingTuple ft = MessageFormatter.format(format, arg1, arg2);
logger.log(FQCN, Level.DEBUG, ft.getMessage(), ft.getThrowable());
}
}
public void debug(String format, Object[] argArray) {
if (logger.isDebugEnabled()) {
FormattingTuple ft = MessageFormatter.arrayFormat(format, argArray);
logger.log(FQCN, Level.DEBUG, ft.getMessage(), ft.getThrowable());
}
}
public void debug(String msg, Throwable t) {
logger.log(FQCN, Level.DEBUG, msg, t);
}
//...省略一堆接口的实现...
}
所以,在开发业务系统或者开发框架、组件的时候,我们统一使用Slf4j提供的接口来编写打印日志的代码,具体使用哪种日志框架实现(log4j、logback……),是可以动态地指定的(使用Java的SPI技术,这里我不多解释,你自行研究吧),只需要将相应的SDK导入到项目中即可。
不过,你可能会说,如果一些老的项目没有使用Slf4j,而是直接使用比如JCL来打印日志,那如果想要替换成其他日志框架,比如log4j,该怎么办呢?实际上,Slf4j不仅仅提供了从其他日志框架到Slf4j的适配器,还提供了反向适配器,也就是从Slf4j到其他日志框架的适配。我们可以先将JCL切换为Slf4j,然后再将Slf4j切换为log4j。经过两次适配器的转换,我们就能成功将log4j切换为了logback。
门面模式
门面模式,也叫外观模式,英文全称是Facade Design Pattern。在GoF的《设计模式》一书中,门面模式是这样定义的:
Provide a unified interface to a set of interfaces in a subsystem. Facade Pattern defines a higher-level interface that makes the subsystem easier to use.
翻译成中文就是:门面模式为子系统提供一组统一的接口,定义一组高层接口让子系统更易用。
假设有一个系统A,提供了a、b、c、d四个接口。系统B完成某个业务功能,需要调用A系统的a、b、d接口。利用门面模式,我们提供一个包裹a、b、d接口调用的门面接口x,给系统B直接使用。
不知道你会不会有这样的疑问,让系统B直接调用a、b、d感觉没有太大问题呀,为什么还要提供一个包裹a、b、d的接口x呢?关于这个问题,我通过一个具体的例子来解释一下。
假设我们刚刚提到的系统A是一个后端服务器,系统B是App客户端。App客户端通过后端服务器提供的接口来获取数据。我们知道,App和服务器之间是通过移动网络通信的,网络通信耗时比较多,为了提高App的响应速度,我们要尽量减少App与服务器之间的网络通信次数。
假设,完成某个业务功能(比如显示某个页面信息)需要“依次”调用a、b、d三个接口,因自身业务的特点,不支持并发调用这三个接口。
如果我们现在发现App客户端的响应速度比较慢,排查之后发现,是因为过多的接口调用过多的网络通信。针对这种情况,我们就可以利用门面模式,让后端服务器提供一个包裹a、b、d三个接口调用的接口x。App客户端调用一次接口x,来获取到所有想要的数据,将网络通信的次数从3次减少到1次,也就提高了App的响应速度。
这里举的例子只是应用门面模式的其中一个意图,也就是解决性能问题。实际上,不同的应用场景下,使用门面模式的意图也不同。
应用场景举例
在GoF给出的定义中提到,“门面模式让子系统更加易用”,实际上,它除了解决易用性问题之外,还能解决其他很多方面的问题。
强调一下,门面模式定义中的“子系统(subsystem)”也可以有多种理解方式。它既可以是一个完整的系统,也可以是更细粒度的类或者模块。
- 解决易用性问题
门面模式可以用来封装系统的底层实现,隐藏系统的复杂性,提供一组更加简单易用、更高层的接口。比如,Linux系统调用函数就可以看作一种“门面”。它是Linux操作系统暴露给开发者的一组“特殊”的编程接口,它封装了底层更基础的Linux内核调用。再比如,Linux的Shell命令,实际上也可以看作一种门面模式的应用。它继续封装系统调用,提供更加友好、简单的命令,让我们可以直接通过执行命令来跟操作系统交互。
我们前面也多次讲过,设计原则、思想、模式很多都是相通的,是同一个道理不同角度的表述。实际上,从隐藏实现复杂性,提供更易用接口这个意图来看,门面模式有点类似之前讲到的迪米特法则(最少知识原则)和接口隔离原则:两个有交互的系统,只暴露有限的必要的接口。除此之外,门面模式还有点类似之前提到封装、抽象的设计思想,提供更抽象的接口,封装底层实现细节。
- 解决性能问题
通过将多个接口调用替换为一个门面接口调用,减少网络通信成本,提高App客户端的响应速度。我们来讨论一下这样一个问题:从代码实现的角度来看,该如何组织门面接口和非门面接口?
如果门面接口不多,我们完全可以将它跟非门面接口放到一块,也不需要特殊标记,当作普通接口来用即可。如果门面接口很多,我们可以在已有的接口之上,再重新抽象出一层,专门放置门面接口,从类、包的命名上跟原来的接口层做区分。如果门面接口特别多,并且很多都是跨多个子系统的,我们可以将门面接口放到一个新的子系统中。
- 解决分布式事务问题
在一个金融系统中,有两个业务领域模型,用户和钱包。这两个业务领域模型都对外暴露了一系列接口,比如用户的增删改查接口、钱包的增删改查接口。假设有这样一个业务场景:在用户注册的时候,我们不仅会创建用户(在数据库User表中),还会给用户创建一个钱包(在数据库的Wallet表中)。
对于这样一个简单的业务需求,我们可以通过依次调用用户的创建接口和钱包的创建接口来完成。但是,用户注册需要支持事务,也就是说,创建用户和钱包的两个操作,要么都成功,要么都失败,不能一个成功、一个失败。
要支持两个接口调用在一个事务中执行,是比较难实现的,这涉及分布式事务问题。虽然我们可以通过引入分布式事务框架或者事后补偿的机制来解决,但代码实现都比较复杂。而最简单的解决方案是,利用数据库事务或者Spring框架提供的事务(如果是Java语言的话),在一个事务中,执行创建用户和创建钱包这两个SQL操作。这就要求两个SQL操作要在一个接口中完成,所以,我们可以借鉴门面模式的思想,再设计一个包裹这两个操作的新接口,让新接口在一个事务中执行两个SQL操作。
组合模式
组合模式(Composite Design Pattern)跟之前讲的面向对象设计中的“组合关系(通过组合来组装两个类)”,完全是两码事。这里讲的“组合模式”,主要是用来处理树形结构数据。这里的“数据”,你可以简单理解为一组对象集合。
正因为其应用场景的特殊性,数据必须能表示成树形结构,这也导致了这种模式在实际的项目开发中并不那么常用。但是,一旦数据满足树形结构,应用这种模式就能发挥很大的作用,能让代码变得非常简洁。
原理与实现
在GoF的《设计模式》一书中,组合模式是这样定义的:
Compose objects into tree structure to represent part-whole hierarchies.Composite lets client treat individual objects and compositions of objects uniformly.
翻译成中文就是:将一组对象组织(Compose)成树形结构,以表示一种“部分-整体”的层次结构。组合让客户端(在很多设计模式书籍中,“客户端”代指代码的使用者。)可以统一单个对象和组合对象的处理逻辑。
假设我们有这样一个需求:设计一个类来表示文件系统中的目录,能方便地实现下面这些功能:
- 动态地添加、删除某个目录下的子目录或文件;
- 统计指定目录下的文件个数;
- 统计指定目录下的文件总大小。
这里给出了这个类的骨架代码,如下所示。其中的核心逻辑并未实现。在下面的代码实现中,我们把文件和目录统一用FileSystemNode类来表示,并且通过isFile属性来区分。
public class FileSystemNode {
private String path;
private boolean isFile;
private List<FileSystemNode> subNodes = new ArrayList<>();
public FileSystemNode(String path, boolean isFile) {
this.path = path;
this.isFile = isFile;
}
public int countNumOfFiles() {
if (isFile) {
return 1;
}
int numOfFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
numOfFiles += fileOrDir.countNumOfFiles();
}
return numOfFiles;
}
public long countSizeOfFiles() {
if (isFile) {
File file = new File(path);
if (!file.exists()) return 0;
return file.length();
}
long sizeofFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
sizeofFiles += fileOrDir.countSizeOfFiles();
}
return sizeofFiles;
}
public String getPath() {
return path;
}
public void addSubNode(FileSystemNode fileOrDir) {
subNodes.add(fileOrDir);
}
public void removeSubNode(FileSystemNode fileOrDir) {
int size = subNodes.size();
int i = 0;
for (; i < size; ++i) {
if (subNodes.get(i).getPath().equalsIgnoreCase(fileOrDir.getPath())) {
break;
}
}
if (i < size) {
subNodes.remove(i);
}
}
}
单纯从功能实现角度来说,上面的代码没有问题,已经实现了我们想要的功能。但是,如果我们开发的是一个大型系统,从扩展性(文件或目录可能会对应不同的操作)、业务建模(文件和目录从业务上是两个概念)、代码的可读性(文件和目录区分对待更加符合人们对业务的认知)的角度来说,我们最好对文件和目录进行区分设计,定义为File和Directory两个类。
按照这个设计思路,我们对代码进行重构。重构之后的代码如下所示:
public abstract class FileSystemNode {
protected String path;
public FileSystemNode(String path) {
this.path = path;
}
public abstract int countNumOfFiles();
public abstract long countSizeOfFiles();
public String getPath() {
return path;
}
}
public class File extends FileSystemNode {
public File(String path) {
super(path);
}
@Override
public int countNumOfFiles() {
return 1;
}
@Override
public long countSizeOfFiles() {
java.io.File file = new java.io.File(path);
if (!file.exists()) return 0;
return file.length();
}
}
public class Directory extends FileSystemNode {
private List<FileSystemNode> subNodes = new ArrayList<>();
public Directory(String path) {
super(path);
}
@Override
public int countNumOfFiles() {
int numOfFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
numOfFiles += fileOrDir.countNumOfFiles();
}
return numOfFiles;
}
@Override
public long countSizeOfFiles() {
long sizeofFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
sizeofFiles += fileOrDir.countSizeOfFiles();
}
return sizeofFiles;
}
public void addSubNode(FileSystemNode fileOrDir) {
subNodes.add(fileOrDir);
}
public void removeSubNode(FileSystemNode fileOrDir) {
int size = subNodes.size();
int i = 0;
for (; i < size; ++i) {
if (subNodes.get(i).getPath().equalsIgnoreCase(fileOrDir.getPath())) {
break;
}
}
if (i < size) {
subNodes.remove(i);
}
}
}
文件和目录类都设计好了,我们来看,如何用它们来表示一个文件系统中的目录树结构。具体的代码示例如下所示:
public class Demo {
public static void main(String[] args) {
/**
* /
* /wz/
* /wz/a.txt
* /wz/b.txt
* /wz/movies/
* /wz/movies/c.avi
* /xzg/
* /xzg/docs/
* /xzg/docs/d.txt
*/
Directory fileSystemTree = new Directory("/");
Directory node_wz = new Directory("/wz/");
Directory node_xzg = new Directory("/xzg/");
fileSystemTree.addSubNode(node_wz);
fileSystemTree.addSubNode(node_xzg);
File node_wz_a = new File("/wz/a.txt");
File node_wz_b = new File("/wz/b.txt");
Directory node_wz_movies = new Directory("/wz/movies/");
node_wz.addSubNode(node_wz_a);
node_wz.addSubNode(node_wz_b);
node_wz.addSubNode(node_wz_movies);
File node_wz_movies_c = new File("/wz/movies/c.avi");
node_wz_movies.addSubNode(node_wz_movies_c);
Directory node_xzg_docs = new Directory("/xzg/docs/");
node_xzg.addSubNode(node_xzg_docs);
File node_xzg_docs_d = new File("/xzg/docs/d.txt");
node_xzg_docs.addSubNode(node_xzg_docs_d);
System.out.println("/ files num:" + fileSystemTree.countNumOfFiles());
System.out.println("/wz/ files num:" + node_wz.countNumOfFiles());
}
}
我们对照着这个例子,再重新看一下组合模式的定义:“将一组对象(文件和目录)组织成树形结构,以表示一种‘部分-整体’的层次结构(目录与子目录的嵌套结构)。组合模式让客户端可以统一单个对象(文件)和组合对象(目录)的处理逻辑(递归遍历)。”
实际上,刚才讲的这种组合模式的设计思路,与其说是一种设计模式,倒不如说是对业务场景的一种数据结构和算法的抽象。其中,数据可以表示成树这种数据结构,业务需求可以通过在树上的递归遍历算法来实现。
应用场景举例
假设我们在开发一个OA系统(办公自动化系统)。公司的组织结构包含部门和员工两种数据类型。其中,部门又可以包含子部门和员工。在数据库中的表结构如下所示:
我们希望在内存中构建整个公司的人员架构图(部门、子部门、员工的隶属关系),并且提供接口计算出部门的薪资成本(隶属于这个部门的所有员工的薪资和)。
部门包含子部门和员工,这是一种嵌套结构,可以表示成树这种数据结构。计算每个部门的薪资开支这样一个需求,也可以通过在树上的遍历算法来实现。所以,从这个角度来看,这个应用场景可以使用组合模式来设计和实现。
这个例子的代码结构跟上一个例子的很相似,代码实现我直接贴在了下面,你可以对比着看一下。其中,HumanResource是部门类(Department)和员工类(Employee)抽象出来的父类,为的是能统一薪资的处理逻辑。Demo中的代码负责从数据库中读取数据并在内存中构建组织架构图。
public abstract class HumanResource {
protected long id;
protected double salary;
public HumanResource(long id) {
this.id = id;
}
public long getId() {
return id;
}
public abstract double calculateSalary();
}
public class Employee extends HumanResource {
public Employee(long id, double salary) {
super(id);
this.salary = salary;
}
@Override
public double calculateSalary() {
return salary;
}
}
public class Department extends HumanResource {
private List<HumanResource> subNodes = new ArrayList<>();
public Department(long id) {
super(id);
}
@Override
public double calculateSalary() {
double totalSalary = 0;
for (HumanResource hr : subNodes) {
totalSalary += hr.calculateSalary();
}
this.salary = totalSalary;
return totalSalary;
}
public void addSubNode(HumanResource hr) {
subNodes.add(hr);
}
}
// 构建组织架构的代码
public class Demo {
private static final long ORGANIZATION_ROOT_ID = 1001;
private DepartmentRepo departmentRepo; // 依赖注入
private EmployeeRepo employeeRepo; // 依赖注入
public void buildOrganization() {
Department rootDepartment = new Department(ORGANIZATION_ROOT_ID);
buildOrganization(rootDepartment);
}
private void buildOrganization(Department department) {
List<Long> subDepartmentIds = departmentRepo.getSubDepartmentIds(department.getId());
for (Long subDepartmentId : subDepartmentIds) {
Department subDepartment = new Department(subDepartmentId);
department.addSubNode(subDepartment);
buildOrganization(subDepartment);
}
List<Long> employeeIds = employeeRepo.getDepartmentEmployeeIds(department.getId());
for (Long employeeId : employeeIds) {
double salary = employeeRepo.getEmployeeSalary(employeeId);
department.addSubNode(new Employee(employeeId, salary));
}
}
}
享元模式
原理与实现
享元模式(Flyweight Design Pattern)顾名思义就是被共享的单元。享元模式的意图是复用对象,节省内存,前提是享元对象是不可变对象。
具体来讲,当一个系统中存在大量重复对象的时候,如果这些重复的对象是不可变对象,我们就可以利用享元模式将对象设计成享元,在内存中只保留一份实例,供多处代码引用。这样可以减少内存中对象的数量,起到节省内存的目的。实际上,不仅仅相同对象可以设计成享元,对于相似对象,我们也可以将这些对象中相同的部分(字段)提取出来,设计成享元,让这些大量相似对象引用这些享元。
定义中的“不可变对象”指的是,一旦通过构造函数初始化完成之后,它的状态(对象的成员变量或者属性)就不会再被修改了。所以,不可变对象不能暴露任何set()等修改内部状态的方法。之所以要求享元是不可变对象,那是因为它会被多处代码共享使用,避免一处代码对享元进行了修改,影响到其他使用它的代码。
假设我们在开发一个棋牌游戏(比如象棋)。一个游戏厅中有成千上万个“房间”,每个房间对应一个棋局。棋局要保存每个棋子的数据,比如:棋子类型(将、相、士、炮等)、棋子颜色(红方、黑方)、棋子在棋局中的位置。利用这些数据,我们就能显示一个完整的棋盘给玩家。具体的代码如下所示。其中,ChessPiece类表示棋子,ChessBoard类表示一个棋局,里面保存了象棋中30个棋子的信息。
public class ChessPiece {//棋子
private int id;
private String text;
private Color color;
private int positionX;
private int positionY;
public ChessPiece(int id, String text, Color color, int positionX, int positionY) {
this.id = id;
this.text = text;
this.color = color;
this.positionX = positionX;
this.positionY = positionX;
}
public static enum Color {
RED, BLACK
}
// ...省略其他属性和getter/setter方法...
}
public class ChessBoard {//棋局
private Map<Integer, ChessPiece> chessPieces = new HashMap<>();
public ChessBoard() {
init();
}
private void init() {
chessPieces.put(1, new ChessPiece(1, "車", ChessPiece.Color.BLACK, 0, 0));
chessPieces.put(2, new ChessPiece(2,"馬", ChessPiece.Color.BLACK, 0, 1));
//...省略摆放其他棋子的代码...
}
public void move(int chessPieceId, int toPositionX, int toPositionY) {
//...省略...
}
}
为了记录每个房间当前的棋局情况,我们需要给每个房间都创建一个ChessBoard棋局对象。因为游戏大厅中有成千上万的房间(实际上,百万人同时在线的游戏大厅也有很多),那保存这么多棋局对象就会消耗大量的内存。有没有什么办法来节省内存呢?
这个时候,享元模式就可以派上用场了。像刚刚的实现方式,在内存中会有大量的相似对象。这些相似对象的id、text、color都是相同的,唯独positionX、positionY不同。实际上,我们可以将棋子的id、text、color属性拆分出来,设计成独立的类,并且作为享元供多个棋盘复用。这样,棋盘只需要记录每个棋子的位置信息就可以了。具体的代码实现如下所示:
// 享元类
public class ChessPieceUnit {
private int id;
private String text;
private Color color;
public ChessPieceUnit(int id, String text, Color color) {
this.id = id;
this.text = text;
this.color = color;
}
public static enum Color {
RED, BLACK
}
// ...省略其他属性和getter方法...
}
public class ChessPieceUnitFactory {
private static final Map<Integer, ChessPieceUnit> pieces = new HashMap<>();
static {
pieces.put(1, new ChessPieceUnit(1, "車", ChessPieceUnit.Color.BLACK));
pieces.put(2, new ChessPieceUnit(2,"馬", ChessPieceUnit.Color.BLACK));
//...省略摆放其他棋子的代码...
}
public static ChessPieceUnit getChessPiece(int chessPieceId) {
return pieces.get(chessPieceId);
}
}
public class ChessPiece {
private ChessPieceUnit chessPieceUnit;
private int positionX;
private int positionY;
public ChessPiece(ChessPieceUnit unit, int positionX, int positionY) {
this.chessPieceUnit = unit;
this.positionX = positionX;
this.positionY = positionY;
}
// 省略getter、setter方法
}
public class ChessBoard {
private Map<Integer, ChessPiece> chessPieces = new HashMap<>();
public ChessBoard() {
init();
}
private void init() {
chessPieces.put(1, new ChessPiece(
ChessPieceUnitFactory.getChessPiece(1), 0,0));
chessPieces.put(1, new ChessPiece(
ChessPieceUnitFactory.getChessPiece(2), 1,0));
//...省略摆放其他棋子的代码...
}
public void move(int chessPieceId, int toPositionX, int toPositionY) {
//...省略...
}
}
在上面的代码实现中,我们利用工厂类来缓存ChessPieceUnit信息(也就是id、text、color)。通过工厂类获取到的ChessPieceUnit就是享元。所有的ChessBoard对象共享这30个ChessPieceUnit对象(因为象棋中只有30个棋子)。在使用享元模式之前,记录1万个棋局,我们要创建30万(30*1万)个棋子的ChessPieceUnit对象。利用享元模式,我们只需要创建30个享元对象供所有棋局共享使用即可,大大节省了内存。
享元模式在文本编辑器中的应用
为了简化需求背景,我们假设这个文本编辑器只实现了文字编辑功能,不包含图片、表格等复杂的编辑功能。对于简化之后的文本编辑器,我们要在内存中表示一个文本文件,只需要记录文字和格式两部分信息就可以了,其中,格式又包括文字的字体、大小、颜色等信息。
尽管在实际的文档编写中,我们一般都是按照文本类型(标题、正文……)来设置文字的格式,标题是一种格式,正文是另一种格式等等。但是,从理论上讲,我们可以给文本文件中的每个文字都设置不同的格式。为了实现如此灵活的格式设置,并且代码实现又不过于太复杂,我们把每个文字都当作一个独立的对象来看待,并且在其中包含它的格式信息。具体的代码示例如下所示:
public class Character {//文字
private char c;
private Font font;
private int size;
private int colorRGB;
public Character(char c, Font font, int size, int colorRGB) {
this.c = c;
this.font = font;
this.size = size;
this.colorRGB = colorRGB;
}
}
public class Editor {
private List<Character> chars = new ArrayList<>();
public void appendCharacter(char c, Font font, int size, int colorRGB) {
Character character = new Character(c, font, size, colorRGB);
chars.add(character);
}
}
在文本编辑器中,我们每敲一个文字,都会调用Editor类中的appendCharacter()方法,创建一个新的Character对象,保存到chars数组中。如果一个文本文件中,有上万、十几万、几十万的文字,那我们就要在内存中存储这么多Character对象。那有没有办法可以节省一点内存呢?
public class CharacterStyle {
private Font font;
private int size;
private int colorRGB;
public CharacterStyle(Font font, int size, int colorRGB) {
this.font = font;
this.size = size;
this.colorRGB = colorRGB;
}
@Override
public boolean equals(Object o) {
CharacterStyle otherStyle = (CharacterStyle) o;
return font.equals(otherStyle.font)
&& size == otherStyle.size
&& colorRGB == otherStyle.colorRGB;
}
}
public class CharacterStyleFactory {
private static final List<CharacterStyle> styles = new ArrayList<>();
public static CharacterStyle getStyle(Font font, int size, int colorRGB) {
CharacterStyle newStyle = new CharacterStyle(font, size, colorRGB);
for (CharacterStyle style : styles) {
if (style.equals(newStyle)) {
return style;
}
}
styles.add(newStyle);
return newStyle;
}
}
public class Character {
private char c;
private CharacterStyle style;
public Character(char c, CharacterStyle style) {
this.c = c;
this.style = style;
}
}
public class Editor {
private List<Character> chars = new ArrayList<>();
public void appendCharacter(char c, Font font, int size, int colorRGB) {
Character character = new Character(c, CharacterStyleFactory.getStyle(font, size, colorRGB));
chars.add(character);
}
}
享元模式vs单例、缓存、对象池
享元模式跟单例的区别。
在单例模式中,一个类只能创建一个对象,而在享元模式中,一个类可以创建多个对象,每个对象被多处代码引用共享。实际上,享元模式有点类似于之前讲到的单例的变体:多例。
我们前面也多次提到,区别两种设计模式,不能光看代码实现,而是要看设计意图,也就是要解决的问题。尽管从代码实现上来看,享元模式和多例有很多相似之处,但从设计意图上来看,它们是完全不同的。应用享元模式是为了对象复用,节省内存,而应用多例模式是为了限制对象的个数。
享元模式跟缓存的区别。
在享元模式的实现中,我们通过工厂类来“缓存”已经创建好的对象。这里的“缓存”实际上是“存储”的意思,跟我们平时所说的“数据库缓存”“CPU缓存”“MemCache缓存”是两回事。我们平时所讲的缓存,主要是为了提高访问效率,而非复用。
享元模式跟对象池的区别。
对象池、连接池(比如数据库连接池)、线程池等也是为了复用,那它们跟享元模式有什么区别呢?
你可能对连接池、线程池比较熟悉,对对象池比较陌生,所以,这里我简单解释一下对象池。像C++这样的编程语言,内存的管理是由程序员负责的。为了避免频繁地进行对象创建和释放导致内存碎片,我们可以预先申请一片连续的内存空间,也就是这里说的对象池。每次创建对象时,我们从对象池中直接取出一个空闲对象来使用,对象使用完成之后,再放回到对象池中以供后续复用,而非直接释放掉。
虽然对象池、连接池、线程池、享元模式都是为了复用,但是,如果我们再细致地抠一抠“复用”这个字眼的话,对象池、连接池、线程池等池化技术中的“复用”和享元模式中的“复用”实际上是不同的概念。
池化技术中的“复用”可以理解为“重复使用”,主要目的是节省时间(比如从数据库池中取一个连接,不需要重新创建)。在任意时刻,每一个对象、连接、线程,并不会被多处使用,而是被一个使用者独占,当使用完成之后,放回到池中,再由其他使用者重复利用。享元模式中的“复用”可以理解为“共享使用”,在整个生命周期中,都是被所有使用者共享的,主要目的是节省空间。
享元模式在Java Integer中的应用
Integer i1 = 56;
Integer i2 = 56;
Integer i3 = 129;
Integer i4 = 129;
System.out.println(i1 == i2);
System.out.println(i3 == i4);
前4行赋值语句都会触发自动装箱操作,也就是会创建Integer对象并且赋值给i1、i2、i3、i4这四个变量。i1、i2存储的数值相同,都是56,也都指向相同的Integer对象,所以通过“==”来判定是否相同的时候,会返回true。i1、i2存储的数值相同,但指向的Integer对象不同,i3==i4判定语句会返回false。实际上,这正是因为Integer用到了享元模式来复用对象,才导致了这样的运行结果。当我们通过自动装箱,也就是调用valueOf()来创建Integer对象的时候,如果要创建的Integer对象的值在-128到127之间,会从IntegerCache类中直接返回,否则才调用new方法创建。看代码更加清晰一些,Integer类的valueOf()函数的具体代码如下所示:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
实际上,这里的IntegerCache相当于,我们上一节课中讲的生成享元对象的工厂类,只不过名字不叫xxxFactory而已。我们来看它的具体代码实现。这个类是Integer的内部类,你也可以自行查看JDK源码。
/**
* Cache to support the object identity semantics of autoboxing for values between
* -128 and 127 (inclusive) as required by JLS.
*
* The cache is initialized on first usage. The size of the cache
* may be controlled by the {@code -XX:AutoBoxCacheMax=<size>} option.
* During VM initialization, java.lang.Integer.IntegerCache.high property
* may be set and saved in the private system properties in the
* sun.misc.VM class.
*/
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
为什么IntegerCache只缓存-128到127之间的整型值呢?
在IntegerCache的代码实现中,当这个类被加载的时候,缓存的享元对象会被集中一次性创建好。毕竟整型值太多了,我们不可能在IntegerCache类中预先创建好所有的整型值,这样既占用太多内存,也使得加载IntegerCache类的时间过长。所以,我们只能选择缓存对于大部分应用来说最常用的整型值,也就是一个字节的大小(-128到127之间的数据)。
实际上,JDK也提供了方法来让我们可以自定义缓存的最大值,有下面两种方式。如果你通过分析应用的JVM内存占用情况,发现-128到255之间的数据占用的内存比较多,你就可以用如下方式,将缓存的最大值从127调整到255。不过,这里注意一下,JDK并没有提供设置最小值的方法。
//方法一:
-Djava.lang.Integer.IntegerCache.high=255
//方法二:
-XX:AutoBoxCacheMax=255
现在,让我们再回到最开始的问题,因为56处于-128和127之间,i1和i2会指向相同的享元对象,所以i1==i2返回true。而129大于127,并不会被缓存,每次都会创建一个全新的对象,也就是说,i3和i4指向不同的Integer对象,所以i3==i4返回false。
实际上,除了Integer类型之外,其他包装器类型,比如Long、Short、Byte等,也都利用了享元模式来缓存-128到127之间的数据。比如,Long类型对应的LongCache享元工厂类及valueOf()函数代码如下所示:
private static class LongCache {
private LongCache(){}
static final Long cache[] = new Long[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Long(i - 128);
}
}
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) { // will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}
在我们平时的开发中,对于下面这样三种创建整型对象的方式,我们优先使用后两种。
Integer a = new Integer(123);
Integer a = 123;
Integer a = Integer.valueOf(123);
第一种创建方式并不会使用到IntegerCache,而后面两种创建方法可以利用IntegerCache缓存,返回共享的对象,以达到节省内存的目的。举一个极端一点的例子,假设程序需要创建1万个-128到127之间的Integer对象。使用第一种创建方式,我们需要分配1万个Integer对象的内存空间;使用后两种创建方式,我们最多只需要分配256个Integer对象的内存空间。
享元模式在Java String中的应用
String s1 = "小争哥";
String s2 = "小争哥";
String s3 = new String("小争哥");
System.out.println(s1 == s2);
System.out.println(s1 == s3);
上面代码的运行结果是:一个true,一个false。跟Integer类的设计思路相似,String类利用享元模式来复用相同的字符串常量(也就是代码中的“小争哥”)。JVM会专门开辟一块存储区来存储字符串常量,这块存储区叫作“字符串常量池”。上面代码对应的内存存储结构如下所示:
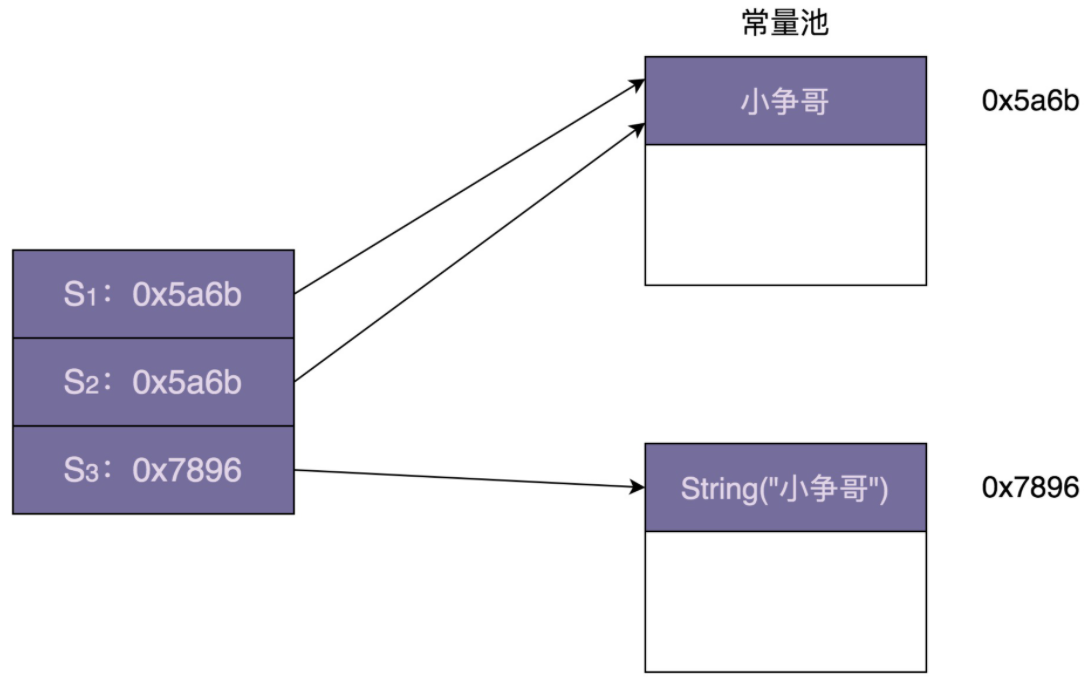
不过,String类的享元模式的设计,跟Integer类稍微有些不同。Integer类中要共享的对象,是在类加载的时候,就集中一次性创建好的。但是,对于字符串来说,我们没法事先知道要共享哪些字符串常量,所以没办法事先创建好,只能在某个字符串常量第一次被用到的时候,存储到常量池中,当之后再用到的时候,直接引用常量池中已经存在的即可,就不需要再重新创建了。
六、设计模式与范式:行为型
观察者模式
原理及应用场景剖析
观察者模式(Observer Design Pattern)也被称为发布订阅模式(Publish-Subscribe Design Pattern)。在GoF的《设计模式》一书中,它的定义是这样的:
Define a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically.
翻译成中文就是:在对象之间定义一个一对多的依赖,当一个对象状态改变的时候,所有依赖的对象都会自动收到通知。
一般情况下,被依赖的对象叫作被观察者(Observable),依赖的对象叫作观察者(Observer)。不过,在实际的项目开发中,这两种对象的称呼是比较灵活的,有各种不同的叫法,比如:Subject-Observer、Publisher-Subscriber、Producer-Consumer、EventEmitter-EventListener、Dispatcher-Listener。不管怎么称呼,只要应用场景符合刚刚给出的定义,都可以看作观察者模式。
我们先来看其中最经典的一种实现方式。这也是在讲到这种模式的时候,很多书籍或资料给出的最常见的实现方式。具体的代码如下所示:
public interface Subject {
void registerObserver(Observer observer);
void removeObserver(Observer observer);
void notifyObservers(Message message);
}
public interface Observer {
void update(Message message);
}
public class ConcreteSubject implements Subject {
private List<Observer> observers = new ArrayList<Observer>();
@Override
public void registerObserver(Observer observer) {
observers.add(observer);
}
@Override
public void removeObserver(Observer observer) {
observers.remove(observer);
}
@Override
public void notifyObservers(Message message) {
for (Observer observer : observers) {
observer.update(message);
}
}
}
public class ConcreteObserverOne implements Observer {
@Override
public void update(Message message) {
//TODO: 获取消息通知,执行自己的逻辑...
System.out.println("ConcreteObserverOne is notified.");
}
}
public class ConcreteObserverTwo implements Observer {
@Override
public void update(Message message) {
//TODO: 获取消息通知,执行自己的逻辑...
System.out.println("ConcreteObserverTwo is notified.");
}
}
public class Demo {
public static void main(String[] args) {
ConcreteSubject subject = new ConcreteSubject();
subject.registerObserver(new ConcreteObserverOne());
subject.registerObserver(new ConcreteObserverTwo());
subject.notifyObservers(new Message());
}
}
假设我们在开发一个P2P投资理财系统,用户注册成功之后,我们会给用户发放投资体验金。代码实现大致是下面这个样子的:
public class UserController {
private UserService userService; // 依赖注入
private PromotionService promotionService; // 依赖注入
public Long register(String telephone, String password) {
//省略输入参数的校验代码
//省略userService.register()异常的try-catch代码
long userId = userService.register(telephone, password);
promotionService.issueNewUserExperienceCash(userId);
return userId;
}
}
虽然注册接口做了两件事情,注册和发放体验金,违反单一职责原则,但是,如果没有扩展和修改的需求,现在的代码实现是可以接受的。如果非得用观察者模式,就需要引入更多的类和更加复杂的代码结构,反倒是一种过度设计。
相反,如果需求频繁变动,比如,用户注册成功之后,不再发放体验金,而是改为发放优惠券,并且还要给用户发送一封“欢迎注册成功”的站内信。这种情况下,我们就需要频繁地修改register()函数中的代码,违反开闭原则。而且,如果注册成功之后需要执行的后续操作越来越多,那register()函数的逻辑会变得越来越复杂,也就影响到代码的可读性和可维护性。
这个时候,观察者模式就能派上用场了。利用观察者模式,我对上面的代码进行了重构。重构之后的代码如下所示:
public interface RegObserver {
void handleRegSuccess(long userId);
}
public class RegPromotionObserver implements RegObserver {
private PromotionService promotionService; // 依赖注入
@Override
public void handleRegSuccess(long userId) {
promotionService.issueNewUserExperienceCash(userId);
}
}
public class RegNotificationObserver implements RegObserver {
private NotificationService notificationService;
@Override
public void handleRegSuccess(long userId) {
notificationService.sendInboxMessage(userId, "Welcome...");
}
}
public class UserController {
private UserService userService; // 依赖注入
private List<RegObserver> regObservers = new ArrayList<>();
// 一次性设置好,之后也不可能动态的修改
public void setRegObservers(List<RegObserver> observers) {
regObservers.addAll(observers);
}
public Long register(String telephone, String password) {
//省略输入参数的校验代码
//省略userService.register()异常的try-catch代码
long userId = userService.register(telephone, password);
for (RegObserver observer : regObservers) {
observer.handleRegSuccess(userId);
}
return userId;
}
}
当我们需要添加新的观察者的时候,比如,用户注册成功之后,推送用户注册信息给大数据征信系统,基于观察者模式的代码实现,UserController类的register()函数完全不需要修改,只需要再添加一个实现了RegObserver接口的类,并且通过setRegObservers()函数将它注册到UserController类中即可。
不过,你可能会说,当我们把发送体验金替换为发送优惠券的时候,需要修改RegPromotionObserver类中handleRegSuccess()函数的代码,这还是违反开闭原则呀?你说得没错,不过,相对于register()函数来说,handleRegSuccess()函数的逻辑要简单很多,修改更不容易出错,引入bug的风险更低。
基于不同应用场景的不同实现方式
观察者模式的应用场景非常广泛,小到代码层面的解耦,大到架构层面的系统解耦,再或者一些产品的设计思路,都有这种模式的影子,比如,邮件订阅、RSS Feeds,本质上都是观察者模式。
不同的应用场景和需求下,这个模式也有截然不同的实现方式,开篇的时候我们也提到,有同步阻塞的实现方式,也有异步非阻塞的实现方式;有进程内的实现方式,也有跨进程的实现方式。
之前讲到的实现方式,从刚刚的分类方式上来看,它是一种同步阻塞的实现方式。观察者和被观察者代码在同一个线程内执行,被观察者一直阻塞,直到所有的观察者代码都执行完成之后,才执行后续的代码。对照上面讲到的用户注册的例子,register()函数依次调用执行每个观察者的handleRegSuccess()函数,等到都执行完成之后,才会返回结果给客户端。
如果注册接口是一个调用比较频繁的接口,对性能非常敏感,希望接口的响应时间尽可能短,那我们可以将同步阻塞的实现方式改为异步非阻塞的实现方式,以此来减少响应时间。具体来讲,当userService.register()函数执行完成之后,我们启动一个新的线程来执行观察者的handleRegSuccess()函数,这样userController.register()函数就不需要等到所有的handleRegSuccess()函数都执行完成之后才返回结果给客户端。userController.register()函数从执行3个SQL语句才返回,减少到只需要执行1个SQL语句就返回,响应时间粗略来讲减少为原来的1/3。
那如何实现一个异步非阻塞的观察者模式呢?简单一点的做法是,在每个handleRegSuccess()函数中,创建一个新的线程执行代码。不过,我们还有更加优雅的实现方式,那就是基于EventBus来实现。
刚刚讲到的两个场景,不管是同步阻塞实现方式还是异步非阻塞实现方式,都是进程内的实现方式。如果用户注册成功之后,我们需要发送用户信息给大数据征信系统,而大数据征信系统是一个独立的系统,跟它之间的交互是跨不同进程的,那如何实现一个跨进程的观察者模式呢?
如果大数据征信系统提供了发送用户注册信息的RPC接口,我们仍然可以沿用之前的实现思路,在handleRegSuccess()函数中调用RPC接口来发送数据。但是,我们还有更加优雅、更加常用的一种实现方式,那就是基于消息队列(Message Queue,比如ActiveMQ)来实现。
当然,这种实现方式也有弊端,那就是需要引入一个新的系统(消息队列),增加了维护成本。不过,它的好处也非常明显。在原来的实现方式中,观察者需要注册到被观察者中,被观察者需要依次遍历观察者来发送消息。而基于消息队列的实现方式,被观察者和观察者解耦更加彻底,两部分的耦合更小。被观察者完全不感知观察者,同理,观察者也完全不感知被观察者。被观察者只管发送消息到消息队列,观察者只管从消息队列中读取消息来执行相应的逻辑。
异步非阻塞观察者模式的简易实现
有两种实现方式。其中一种是:在每个handleRegSuccess()函数中创建一个新的线程执行代码逻辑;另一种是:在UserController的register()函数中使用线程池来执行每个观察者的handleRegSuccess()函数。两种实现方式的具体代码如下所示:
// 第一种实现方式,其他类代码不变,就没有再重复罗列
public class RegPromotionObserver implements RegObserver {
private PromotionService promotionService; // 依赖注入
@Override
public void handleRegSuccess(Long userId) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
promotionService.issueNewUserExperienceCash(userId);
}
});
thread.start();
}
}
// 第二种实现方式,其他类代码不变,就没有再重复罗列
public class UserController {
private UserService userService; // 依赖注入
private List<RegObserver> regObservers = new ArrayList<>();
private Executor executor;
public UserController(Executor executor) {
this.executor = executor;
}
public void setRegObservers(List<RegObserver> observers) {
regObservers.addAll(observers);
}
public Long register(String telephone, String password) {
//省略输入参数的校验代码
//省略userService.register()异常的try-catch代码
long userId = userService.register(telephone, password);
for (RegObserver observer : regObservers) {
executor.execute(new Runnable() {
@Override
public void run() {
observer.handleRegSuccess(userId);
}
});
}
return userId;
}
}
对于第一种实现方式,频繁地创建和销毁线程比较耗时,并且并发线程数无法控制,创建过多的线程会导致堆栈溢出。第二种实现方式,尽管利用了线程池解决了第一种实现方式的问题,但线程池、异步执行逻辑都耦合在了register()函数中,增加了这部分业务代码的维护成本。
如果我们的需求更加极端一点,需要在同步阻塞和异步非阻塞之间灵活切换,那就要不停地修改UserController的代码。除此之外,如果在项目中,不止一个业务模块需要用到异步非阻塞观察者模式,那这样的代码实现也无法做到复用。
我们知道,框架的作用有:隐藏实现细节,降低开发难度,做到代码复用,解耦业务与非业务代码,让程序员聚焦业务开发。针对异步非阻塞观察者模式,我们也可以将它抽象成框架来达到这样的效果
EventBus框架功能需求介绍
EventBus翻译为“事件总线”,它提供了实现观察者模式的骨架代码。我们可以基于此框架,非常容易地在自己的业务场景中实现观察者模式,不需要从零开始开发。其中,Google Guava EventBus就是一个比较著名的EventBus框架,它不仅仅支持异步非阻塞模式,同时也支持同步阻塞模式
public class UserController {
private UserService userService; // 依赖注入
private EventBus eventBus;
private static final int DEFAULT_EVENTBUS_THREAD_POOL_SIZE = 20;
public UserController() {
//eventBus = new EventBus(); // 同步阻塞模式
eventBus = new AsyncEventBus(Executors.newFixedThreadPool(DEFAULT_EVENTBUS_THREAD_POOL_SIZE)); // 异步非阻塞模式
}
public void setRegObservers(List<Object> observers) {
for (Object observer : observers) {
eventBus.register(observer);
}
}
public Long register(String telephone, String password) {
//省略输入参数的校验代码
//省略userService.register()异常的try-catch代码
long userId = userService.register(telephone, password);
eventBus.post(userId);
return userId;
}
}
public class RegPromotionObserver {
private PromotionService promotionService; // 依赖注入
@Subscribe
public void handleRegSuccess(Long userId) {
promotionService.issueNewUserExperienceCash(userId);
}
}
public class RegNotificationObserver {
private NotificationService notificationService;
@Subscribe
public void handleRegSuccess(Long userId) {
notificationService.sendInboxMessage(userId, "...");
}
}
利用EventBus框架实现的观察者模式,跟从零开始编写的观察者模式相比,从大的流程上来说,实现思路大致一样,都需要定义Observer,并且通过register()函数注册Observer,也都需要通过调用某个函数(比如,EventBus中的post()函数)来给Observer发送消息(在EventBus中消息被称作事件event)。
但在实现细节方面,它们又有些区别。基于EventBus,我们不需要定义Observer接口,任意类型的对象都可以注册到EventBus中,通过@Subscribe注解来标明类中哪个函数可以接收被观察者发送的消息。
接下来,我们详细地讲一下,Guava EventBus的几个主要的类和函数。
- EventBus、AsyncEventBus
Guava EventBus对外暴露的所有可调用接口,都封装在EventBus类中。其中,EventBus实现了同步阻塞的观察者模式,AsyncEventBus继承自EventBus,提供了异步非阻塞的观察者模式。具体使用方式如下所示:
EventBus eventBus = new EventBus(); // 同步阻塞模式
EventBus eventBus = new AsyncEventBus(Executors.newFixedThreadPool(8));// 异步阻塞模式
- register()函数
EventBus类提供了register()函数用来注册观察者。具体的函数定义如下所示。它可以接受任何类型(Object)的观察者。而在经典的观察者模式的实现中,register()函数必须接受实现了同一Observer接口的类对象。
public void register(Object object);
- unregister()函数
相对于register()函数,unregister()函数用来从EventBus中删除某个观察者。我就不多解释了,具体的函数定义如下所示:
public void unregister(Object object);
- post()函数
EventBus类提供了post()函数,用来给观察者发送消息。具体的函数定义如下所示:
public void post(Object event);
跟经典的观察者模式的不同之处在于,当我们调用post()函数发送消息的时候,并非把消息发送给所有的观察者,而是发送给可匹配的观察者。所谓可匹配指的是,能接收的消息类型是发送消息(post函数定义中的event)类型的父类。
比如,AObserver能接收的消息类型是XMsg,BObserver能接收的消息类型是YMsg,CObserver能接收的消息类型是ZMsg。其中,XMsg是YMsg的父类。当我们如下发送消息的时候,相应能接收到消息的可匹配观察者如下所示:
XMsg xMsg = new XMsg();
YMsg yMsg = new YMsg();
ZMsg zMsg = new ZMsg();
post(xMsg); => AObserver接收到消息
post(yMsg); => AObserver、BObserver接收到消息
post(zMsg); => CObserver接收到消息
你可能会问,每个Observer能接收的消息类型是在哪里定义的呢?我们来看下Guava EventBus最特别的一个地方,那就是@Subscribe注解。
- @Subscribe注解
EventBus通过@Subscribe注解来标明,某个函数能接收哪种类型的消息。具体的使用代码如下所示。在DObserver类中,我们通过@Subscribe注解了两个函数f1()、f2()。
public DObserver {
//...省略其他属性和方法...
@Subscribe
public void f1(PMsg event) { //... }
@Subscribe
public void f2(QMsg event) { //... }
}
当通过register()函数将DObserver 类对象注册到EventBus的时候,EventBus会根据@Subscribe注解找到f1()和f2(),并且将两个函数能接收的消息类型记录下来(PMsg->f1,QMsg->f2)。当我们通过post()函数发送消息(比如QMsg消息)的时候,EventBus会通过之前的记录(QMsg->f2),调用相应的函数(f2)。
手把手实现一个EventBus框架
我们重点来看,EventBus中两个核心函数register()和post()的实现原理。弄懂了它们,基本上就弄懂了整个EventBus框架。下面两张图是这两个函数的实现原理图。
从图中我们可以看出,最关键的一个数据结构是Observer注册表,记录了消息类型和可接收消息函数的对应关系。当调用register()函数注册观察者的时候,EventBus通过解析@Subscribe注解,生成Observer注册表。当调用post()函数发送消息的时候,EventBus通过注册表找到相应的可接收消息的函数,然后通过Java的反射语法来动态地创建对象、执行函数。对于同步阻塞模式,EventBus在一个线程内依次执行相应的函数。对于异步非阻塞模式,EventBus通过一个线程池来执行相应的函数。
弄懂了原理,实现起来就简单多了。整个小框架的代码实现包括5个类:EventBus、AsyncEventBus、Subscribe、ObserverAction、ObserverRegistry。接下来,我们依次来看下这5个类。
- Subscribe
Subscribe是一个注解,用于标明观察者中的哪个函数可以接收消息。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Beta
public @interface Subscribe {}
- ObserverActio
ObserverAction类用来表示@Subscribe注解的方法,其中,target表示观察者类,method表示方法。它主要用在ObserverRegistry观察者注册表中。
public class ObserverAction {
private Object target;
private Method method;
public ObserverAction(Object target, Method method) {
this.target = Preconditions.checkNotNull(target);
this.method = method;
this.method.setAccessible(true);
}
public void execute(Object event) { // event是method方法的参数
try {
method.invoke(target, event);
} catch (InvocationTargetException | IllegalAccessException e) {
e.printStackTrace();
}
}
}
- ObserverRegistry
ObserverRegistry类就是前面讲到的Observer注册表,是最复杂的一个类,框架中几乎所有的核心逻辑都在这个类中。这个类大量使用了Java的反射语法,不过代码整体来说都不难理解,其中,一个比较有技巧的地方是CopyOnWriteArraySet的使用。
CopyOnWriteArraySet,顾名思义,在写入数据的时候,会创建一个新的set,并且将原始数据clone到新的set中,在新的set中写入数据完成之后,再用新的set替换老的set。这样就能保证在写入数据的时候,不影响数据的读取操作,以此来解决读写并发问题。除此之外,CopyOnWriteSet还通过加锁的方式,避免了并发写冲突。具体的作用你可以去查看一下CopyOnWriteSet类的源码,一目了然。
public class ObserverRegistry {
private ConcurrentMap<Class<?>, CopyOnWriteArraySet<ObserverAction>> registry = new ConcurrentHashMap<>();
public void register(Object observer) {
Map<Class<?>, Collection<ObserverAction>> observerActions = findAllObserverActions(observer);
for (Map.Entry<Class<?>, Collection<ObserverAction>> entry : observerActions.entrySet()) {
Class<?> eventType = entry.getKey();
Collection<ObserverAction> eventActions = entry.getValue();
CopyOnWriteArraySet<ObserverAction> registeredEventActions = registry.get(eventType);
if (registeredEventActions == null) {
registry.putIfAbsent(eventType, new CopyOnWriteArraySet<>());
registeredEventActions = registry.get(eventType);
}
registeredEventActions.addAll(eventActions);
}
}
public List<ObserverAction> getMatchedObserverActions(Object event) {
List<ObserverAction> matchedObservers = new ArrayList<>();
Class<?> postedEventType = event.getClass();
for (Map.Entry<Class<?>, CopyOnWriteArraySet<ObserverAction>> entry : registry.entrySet()) {
Class<?> eventType = entry.getKey();
Collection<ObserverAction> eventActions = entry.getValue();
if (postedEventType.isAssignableFrom(eventType)) {
matchedObservers.addAll(eventActions);
}
}
return matchedObservers;
}
private Map<Class<?>, Collection<ObserverAction>> findAllObserverActions(Object observer) {
Map<Class<?>, Collection<ObserverAction>> observerActions = new HashMap<>();
Class<?> clazz = observer.getClass();
for (Method method : getAnnotatedMethods(clazz)) {
Class<?>[] parameterTypes = method.getParameterTypes();
Class<?> eventType = parameterTypes[0];
if (!observerActions.containsKey(eventType)) {
observerActions.put(eventType, new ArrayList<>());
}
observerActions.get(eventType).add(new ObserverAction(observer, method));
}
return observerActions;
}
private List<Method> getAnnotatedMethods(Class<?> clazz) {
List<Method> annotatedMethods = new ArrayList<>();
for (Method method : clazz.getDeclaredMethods()) {
if (method.isAnnotationPresent(Subscribe.class)) {
Class<?>[] parameterTypes = method.getParameterTypes();
Preconditions.checkArgument(parameterTypes.length == 1,
"Method %s has @Subscribe annotation but has %s parameters."
+ "Subscriber methods must have exactly 1 parameter.",
method, parameterTypes.length);
annotatedMethods.add(method);
}
}
return annotatedMethods;
}
}
- EventBus
EventBus实现的是阻塞同步的观察者模式。看代码你可能会有些疑问,这明明就用到了线程池Executor啊。实际上,MoreExecutors.directExecutor()是Google Guava提供的工具类,看似是多线程,实际上是单线程。之所以要这么实现,主要还是为了跟AsyncEventBus统一代码逻辑,做到代码复用。
public class EventBus {
private Executor executor;
private ObserverRegistry registry = new ObserverRegistry();
public EventBus() {
this(MoreExecutors.directExecutor());
}
protected EventBus(Executor executor) {
this.executor = executor;
}
public void register(Object object) {
registry.register(object);
}
public void post(Object event) {
List<ObserverAction> observerActions = registry.getMatchedObserverActions(event);
for (ObserverAction observerAction : observerActions) {
executor.execute(new Runnable() {
@Override
public void run() {
observerAction.execute(event);
}
});
}
}
}
- AsyncEventBus
有了EventBus,AsyncEventBus的实现就非常简单了。为了实现异步非阻塞的观察者模式,它就不能再继续使用MoreExecutors.directExecutor()了,而是需要在构造函数中,由调用者注入线程池。
public class AsyncEventBus extends EventBus {
public AsyncEventBus(Executor executor) {
super(executor);
}
}
至此,我们用了不到200行代码,就实现了一个还算凑活能用的EventBus,从功能上来讲,它跟Google Guava EventBus几乎一样。不过,如果去查看Google Guava EventBus的源码,你会发现,在实现细节方面,相比我们现在的实现,它其实做了很多优化,比如优化了在注册表中查找消息可匹配函数的算法。
模板模式
模板模式的原理与实现
模板模式,全称是模板方法设计模式,英文是Template Method Design Pattern。在GoF的《设计模式》一书中,它是这么定义的:
Define the skeleton of an algorithm in an operation, deferring some steps to subclasses. Template Method lets subclasses redefine certain steps of an algorithm without changing the algorithm’s structure.
翻译成中文就是:模板方法模式在一个方法中定义一个算法骨架,并将某些步骤推迟到子类中实现。模板方法模式可以让子类在不改变算法整体结构的情况下,重新定义算法中的某些步骤。
这里的“算法”,我们可以理解为广义上的“业务逻辑”,并不特指数据结构和算法中的“算法”。这里的算法骨架就是“模板”,包含算法骨架的方法就是“模板方法”,这也是模板方法模式名字的由来。
原理很简单,代码实现就更加简单。templateMethod()函数定义为final,是为了避免子类重写它。method1()和method2()定义为abstract,是为了强迫子类去实现。不过,这些都不是必须的,在实际的项目开发中,模板模式的代码实现比较灵活,待会儿讲到应用场景的时候,我们会有具体的体现。
public abstract class AbstractClass {
public final void templateMethod() {
//...
method1();
//...
method2();
//...
}
protected abstract void method1();
protected abstract void method2();
}
public class ConcreteClass1 extends AbstractClass {
@Override
protected void method1() {
//...
}
@Override
protected void method2() {
//...
}
}
public class ConcreteClass2 extends AbstractClass {
@Override
protected void method1() {
//...
}
@Override
protected void method2() {
//...
}
}
AbstractClass demo = ConcreteClass1();
demo.templateMethod();
模板模式作用一:复用
模板模式把一个算法中不变的流程抽象到父类的模板方法templateMethod()中,将可变的部分method1()、method2()留给子类ContreteClass1和ContreteClass2来实现。所有的子类都可以复用父类中模板方法定义的流程代码。我们通过两个小例子来更直观地体会一下。
1. Java InputStream
在代码中,read()函数是一个模板方法,定义了读取数据的整个流程,并且暴露了一个可以由子类来定制的抽象方法。不过这个方法也被命名为了read(),只是参数跟模板方法不同。
public abstract class InputStream implements Closeable {
//...省略其他代码...
public int read(byte b[], int off, int len) throws IOException {
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int c = read();
if (c == -1) {
return -1;
}
b[off] = (byte)c;
int i = 1;
try {
for (; i < len ; i++) {
c = read();
if (c == -1) {
break;
}
b[off + i] = (byte)c;
}
} catch (IOException ee) {
}
return i;
}
public abstract int read() throws IOException;
}
public class ByteArrayInputStream extends InputStream {
//...省略其他代码...
@Override
public synchronized int read() {
return (pos < count) ? (buf[pos++] & 0xff) : -1;
}
}
2. Java AbstractList
在Java AbstractList类中,addAll()函数可以看作模板方法,add()是子类需要重写的方法,尽管没有声明为abstract的,但函数实现直接抛出了UnsupportedOperationException异常。如果子类不重写是不能使用的。
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
boolean modified = false;
for (E e : c) {
add(index++, e);
modified = true;
}
return modified;
}
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
模板模式作用二:扩展
这里所说的扩展,并不是指代码的扩展性,而是指框架的扩展性。基于这个作用,模板模式常用在框架的开发中,让框架用户可以在不修改框架源码的情况下,定制化框架的功能。
Java Servlet
如果我们抛开这些高级框架来开发Web项目,必然会用到Servlet。实际上,使用比较底层的Servlet来开发Web项目也不难。我们只需要定义一个继承HttpServlet的类,并且重写其中的doGet()或doPost()方法,来分别处理get和post请求。
public class HelloServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
this.doPost(req, resp);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.getWriter().write("Hello World.");
}
}
除此之外,我们还需要在配置文件web.xml中做如下配置。Tomcat、Jetty等Servlet容器在启动的时候,会自动加载这个配置文件中的URL和Servlet之间的映射关系。
<servlet>
<servlet-name>HelloServlet</servlet-name>
<servlet-class>com.xzg.cd.HelloServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HelloServlet</servlet-name>
<url-pattern>/hello</url-pattern>
</servlet-mapping>
当我们在浏览器中输入网址(比如,http://127.0.0.1:8080/hello)的时候,Servlet容器会接收到相应的请求,并且根据URL和Servlet之间的映射关系,找到相应的Servlet(HelloServlet),然后执行它的service()方法。service()方法定义在父类HttpServlet中,它会调用doGet()或doPost()方法,然后输出数据(“Hello world”)到网页。
我们现在来看,HttpServlet的service()函数长什么样子。
public void service(ServletRequest req, ServletResponse res)
throws ServletException, IOException
{
HttpServletRequest request;
HttpServletResponse response;
if (!(req instanceof HttpServletRequest &&
res instanceof HttpServletResponse)) {
throw new ServletException("non-HTTP request or response");
}
request = (HttpServletRequest) req;
response = (HttpServletResponse) res;
service(request, response);
}
protected void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String method = req.getMethod();
if (method.equals(METHOD_GET)) {
long lastModified = getLastModified(req);
if (lastModified == -1) {
// servlet doesn't support if-modified-since, no reason
// to go through further expensive logic
doGet(req, resp);
} else {
long ifModifiedSince = req.getDateHeader(HEADER_IFMODSINCE);
if (ifModifiedSince < lastModified) {
// If the servlet mod time is later, call doGet()
// Round down to the nearest second for a proper compare
// A ifModifiedSince of -1 will always be less
maybeSetLastModified(resp, lastModified);
doGet(req, resp);
} else {
resp.setStatus(HttpServletResponse.SC_NOT_MODIFIED);
}
}
} else if (method.equals(METHOD_HEAD)) {
long lastModified = getLastModified(req);
maybeSetLastModified(resp, lastModified);
doHead(req, resp);
} else if (method.equals(METHOD_POST)) {
doPost(req, resp);
} else if (method.equals(METHOD_PUT)) {
doPut(req, resp);
} else if (method.equals(METHOD_DELETE)) {
doDelete(req, resp);
} else if (method.equals(METHOD_OPTIONS)) {
doOptions(req,resp);
} else if (method.equals(METHOD_TRACE)) {
doTrace(req,resp);
} else {
String errMsg = lStrings.getString("http.method_not_implemented");
Object[] errArgs = new Object[1];
errArgs[0] = method;
errMsg = MessageFormat.format(errMsg, errArgs);
resp.sendError(HttpServletResponse.SC_NOT_IMPLEMENTED, errMsg);
}
}
从上面的代码中我们可以看出,HttpServlet的service()方法就是一个模板方法,它实现了整个HTTP请求的执行流程,doGet()、doPost()是模板中可以由子类来定制的部分。实际上,这就相当于Servlet框架提供了一个扩展点(doGet()、doPost()方法),让框架用户在不用修改Servlet框架源码的情况下,将业务代码通过扩展点镶嵌到框架中执行。
JUnit TestCase
跟Java Servlet类似,JUnit框架也通过模板模式提供了一些功能扩展点(setUp()、tearDown()等),让框架用户可以在这些扩展点上扩展功能。
在使用JUnit测试框架来编写单元测试的时候,我们编写的测试类都要继承框架提供的TestCase类。在TestCase类中,runBare()函数是模板方法,它定义了执行测试用例的整体流程:先执行setUp()做些准备工作,然后执行runTest()运行真正的测试代码,最后执行tearDown()做扫尾工作。
TestCase类的具体代码如下所示。尽管setUp()、tearDown()并不是抽象函数,还提供了默认的实现,不强制子类去重新实现,但这部分也是可以在子类中定制的,所以也符合模板模式的定义。
public abstract class TestCase extends Assert implements Test {
public void runBare() throws Throwable {
Throwable exception = null;
setUp();
try {
runTest();
} catch (Throwable running) {
exception = running;
} finally {
try {
tearDown();
} catch (Throwable tearingDown) {
if (exception == null) exception = tearingDown;
}
}
if (exception != null) throw exception;
}
/**
* Sets up the fixture, for example, open a network connection.
* This method is called before a test is executed.
*/
protected void setUp() throws Exception {
}
/**
* Tears down the fixture, for example, close a network connection.
* This method is called after a test is executed.
*/
protected void tearDown() throws Exception {
}
}
回调(Callback)的原理解析
相对于普通的函数调用来说,回调是一种双向调用关系。A类事先注册某个函数F到B类,A类在调用B类的P函数的时候,B类反过来调用A类注册给它的F函数。这里的F函数就是“回调函数”。A调用B,B反过来又调用A,这种调用机制就叫作“回调”。
A类如何将回调函数传递给B类呢?不同的编程语言,有不同的实现方法。C语言可以使用函数指针,Java则需要使用包裹了回调函数的类对象,我们简称为回调对象。Java代码如下所示:
public interface ICallback {
void methodToCallback();
}
public class BClass {
public void process(ICallback callback) {
//...
callback.methodToCallback();
//...
}
}
public class AClass {
public static void main(String[] args) {
BClass b = new BClass();
b.process(new ICallback() { //回调对象
@Override
public void methodToCallback() {
System.out.println("Call back me.");
}
});
}
}
从代码实现中,我们可以看出,回调跟模板模式一样,也具有复用和扩展的功能。除了回调函数之外,BClass类的process()函数中的逻辑都可以复用。如果ICallback、BClass类是框架代码,AClass是使用框架的客户端代码,我们可以通过ICallback定制process()函数,也就是说,框架因此具有了扩展的能力。
实际上,回调不仅可以应用在代码设计上,在更高层次的架构设计上也比较常用。比如,通过三方支付系统来实现支付功能,用户在发起支付请求之后,一般不会一直阻塞到支付结果返回,而是注册回调接口(类似回调函数,一般是一个回调用的URL)给三方支付系统,等三方支付系统执行完成之后,将结果通过回调接口返回给用户。
回调可以分为同步回调和异步回调(或者延迟回调)。同步回调指在函数返回之前执行回调函数;异步回调指的是在函数返回之后执行回调函数。上面的代码实际上是同步回调的实现方式,在process()函数返回之前,执行完回调函数methodToCallback()。而上面支付的例子是异步回调的实现方式,发起支付之后不需要等待回调接口被调用就直接返回。从应用场景上来看,同步回调看起来更像模板模式,异步回调看起来更像观察者模式。
应用举例一:JdbcTemplate
Spring提供了很多Template类,比如,JdbcTemplate、RedisTemplate、RestTemplate。尽管都叫作xxxTemplate,但它们并非基于模板模式来实现的,而是基于回调来实现的,确切地说应该是同步回调。
我们拿其中的JdbcTemplate来举例分析一下。Java提供了JDBC类库来封装不同类型的数据库操作。不过,直接使用JDBC来编写操作数据库的代码,还是有点复杂的。比如,下面这段是使用JDBC来查询用户信息的代码。
public class JdbcDemo {
public User queryUser(long id) {
Connection conn = null;
Statement stmt = null;
try {
//1.加载驱动
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/demo", "xzg", "xzg");
//2.创建statement类对象,用来执行SQL语句
stmt = conn.createStatement();
//3.ResultSet类,用来存放获取的结果集
String sql = "select * from user where id=" + id;
ResultSet resultSet = stmt.executeQuery(sql);
String eid = null, ename = null, price = null;
while (resultSet.next()) {
User user = new User();
user.setId(resultSet.getLong("id"));
user.setName(resultSet.getString("name"));
user.setTelephone(resultSet.getString("telephone"));
return user;
}
} catch (ClassNotFoundException e) {
// TODO: log...
} catch (SQLException e) {
// TODO: log...
} finally {
if (conn != null)
try {
conn.close();
} catch (SQLException e) {
// TODO: log...
}
if (stmt != null)
try {
stmt.close();
} catch (SQLException e) {
// TODO: log...
}
}
return null;
}
}
queryUser()函数包含很多流程性质的代码,跟业务无关,比如,加载驱动、创建数据库连接、创建statement、关闭连接、关闭statement、处理异常。针对不同的SQL执行请求,这些流程性质的代码是相同的、可以复用的,我们不需要每次都重新敲一遍。
针对这个问题,Spring提供了JdbcTemplate,对JDBC进一步封装,来简化数据库编程。使用JdbcTemplate查询用户信息,我们只需要编写跟这个业务有关的代码,其中包括,查询用户的SQL语句、查询结果与User对象之间的映射关系。其他流程性质的代码都封装在了JdbcTemplate类中,不需要我们每次都重新编写。用JdbcTemplate重写上面的例子,如下所示:
public class JdbcTemplateDemo {
private JdbcTemplate jdbcTemplate;
public User queryUser(long id) {
String sql = "select * from user where id="+id;
return jdbcTemplate.query(sql, new UserRowMapper()).get(0);
}
class UserRowMapper implements RowMapper<User> {
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getLong("id"));
user.setName(rs.getString("name"));
user.setTelephone(rs.getString("telephone"));
return user;
}
}
}
那JdbcTemplate底层具体是如何实现的呢?JdbcTemplate通过回调的机制,将不变的执行流程抽离出来,放到模板方法execute()中,将可变的部分设计成回调StatementCallback,由用户来定制。query()函数是对execute()函数的二次封装,让接口用起来更加方便。
@Override
public <T> List<T> query(String sql, RowMapper<T> rowMapper) throws DataAccessException {
return query(sql, new RowMapperResultSetExtractor<T>(rowMapper));
}
@Override
public <T> T query(final String sql, final ResultSetExtractor<T> rse) throws DataAccessException {
Assert.notNull(sql, "SQL must not be null");
Assert.notNull(rse, "ResultSetExtractor must not be null");
if (logger.isDebugEnabled()) {
logger.debug("Executing SQL query [" + sql + "]");
}
class QueryStatementCallback implements StatementCallback<T>, SqlProvider {
@Override
public T doInStatement(Statement stmt) throws SQLException {
ResultSet rs = null;
try {
rs = stmt.executeQuery(sql);
ResultSet rsToUse = rs;
if (nativeJdbcExtractor != null) {
rsToUse = nativeJdbcExtractor.getNativeResultSet(rs);
}
return rse.extractData(rsToUse);
}
finally {
JdbcUtils.closeResultSet(rs);
}
}
@Override
public String getSql() {
return sql;
}
}
return execute(new QueryStatementCallback());
}
@Override
public <T> T execute(StatementCallback<T> action) throws DataAccessException {
Assert.notNull(action, "Callback object must not be null");
Connection con = DataSourceUtils.getConnection(getDataSource());
Statement stmt = null;
try {
Connection conToUse = con;
if (this.nativeJdbcExtractor != null &&
this.nativeJdbcExtractor.isNativeConnectionNecessaryForNativeStatements()) {
conToUse = this.nativeJdbcExtractor.getNativeConnection(con);
}
stmt = conToUse.createStatement();
applyStatementSettings(stmt);
Statement stmtToUse = stmt;
if (this.nativeJdbcExtractor != null) {
stmtToUse = this.nativeJdbcExtractor.getNativeStatement(stmt);
}
T result = action.doInStatement(stmtToUse);
handleWarnings(stmt);
return result;
}
catch (SQLException ex) {
// Release Connection early, to avoid potential connection pool deadlock
// in the case when the exception translator hasn't been initialized yet.
JdbcUtils.closeStatement(stmt);
stmt = null;
DataSourceUtils.releaseConnection(con, getDataSource());
con = null;
throw getExceptionTranslator().translate("StatementCallback", getSql(action), ex);
}
finally {
JdbcUtils.closeStatement(stmt);
DataSourceUtils.releaseConnection(con, getDataSource());
}
}
应用举例二:setClickListener()
在客户端开发中,我们经常给控件注册事件监听器,比如下面这段代码,就是在Android应用开发中,给Button控件的点击事件注册监听器。
Button button = (Button)findViewById(R.id.button);
button.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
System.out.println("I am clicked.");
}
});
从代码结构上来看,事件监听器很像回调,即传递一个包含回调函数(onClick())的对象给另一个函数。从应用场景上来看,它又很像观察者模式,即事先注册观察者(OnClickListener),当用户点击按钮的时候,发送点击事件给观察者,并且执行相应的onClick()函数。
前面讲到,回调分为同步回调和异步回调。这里的回调算是异步回调。
应用举例三:addShutdownHook()
Hook可以翻译成“钩子”,那它跟Callback有什么区别呢?
网上有人认为Hook就是Callback,两者说的是一回事儿,只是表达不同而已。而有人觉得Hook是Callback的一种应用。Callback更侧重语法机制的描述,Hook更加侧重应用场景的描述。
Hook比较经典的应用场景是Tomcat和JVM的shutdown hook。接下来,我们拿JVM来举例说明一下。JVM提供了Runtime.addShutdownHook(Thread hook)方法,可以注册一个JVM关闭的Hook。当应用程序关闭的时候,JVM会自动调用Hook代码。代码示例如下所示:
public class ShutdownHookDemo {
private static class ShutdownHook extends Thread {
public void run() {
System.out.println("I am called during shutting down.");
}
}
public static void main(String[] args) {
Runtime.getRuntime().addShutdownHook(new ShutdownHook());
}
}
再来看addShutdownHook()的代码实现,如下所示。
public class Runtime {
public void addShutdownHook(Thread hook) {
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
sm.checkPermission(new RuntimePermission("shutdownHooks"));
}
ApplicationShutdownHooks.add(hook);
}
}
class ApplicationShutdownHooks {
/* The set of registered hooks */
private static IdentityHashMap<Thread, Thread> hooks;
static {
hooks = new IdentityHashMap<>();
} catch (IllegalStateException e) {
hooks = null;
}
}
static synchronized void add(Thread hook) {
if(hooks == null)
throw new IllegalStateException("Shutdown in progress");
if (hook.isAlive())
throw new IllegalArgumentException("Hook already running");
if (hooks.containsKey(hook))
throw new IllegalArgumentException("Hook previously registered");
hooks.put(hook, hook);
}
static void runHooks() {
Collection<Thread> threads;
synchronized(ApplicationShutdownHooks.class) {
threads = hooks.keySet();
hooks = null;
}
for (Thread hook : threads) {
hook.start();
}
for (Thread hook : threads) {
while (true) {
try {
hook.join();
break;
} catch (InterruptedException ignored) {
}
}
}
}
}
从代码中我们可以发现,有关Hook的逻辑都被封装到ApplicationShutdownHooks类中了。当应用程序关闭的时候,JVM会调用这个类的runHooks()方法,创建多个线程,并发地执行多个Hook。在注册完Hook之后,并不需要等待Hook执行完成,所以,这也算是一种异步回调。
模板模式 VS 回调
从应用场景上来看,同步回调跟模板模式几乎一致。它们都是在一个大的算法骨架中,自由替换其中的某个步骤,起到代码复用和扩展的目的。而异步回调跟模板模式有较大差别,更像是观察者模式。
从代码实现上来看,回调和模板模式完全不同。回调基于组合关系来实现,把一个对象传递给另一个对象,是一种对象之间的关系;模板模式基于继承关系来实现,子类重写父类的抽象方法,是一种类之间的关系。
前面也讲到,组合优于继承。实际上,这里也不例外。在代码实现上,回调相对于模板模式会更加灵活,主要体现在下面几点。
- 像Java这种只支持单继承的语言,基于模板模式编写的子类,已经继承了一个父类,不再具有继承的能力。
- 回调可以使用匿名类来创建回调对象,可以不用事先定义类;而模板模式针对不同的实现都要定义不同的子类。
- 如果某个类中定义了多个模板方法,每个方法都有对应的抽象方法,那即便我们只用到其中的一个模板方法,子类也必须实现所有的抽象方法。而回调就更加灵活,只需要往用到的模板方法中注入回调对象即可。
策略模式
策略模式的原理与实现
策略模式,英文全称是Strategy Design Pattern。在GoF的《设计模式》一书中,它是这样定义的:
Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it.
翻译成中文就是:定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用它们的客户端(这里的客户端代指使用算法的代码)。
我们知道,工厂模式是解耦对象的创建和使用,观察者模式是解耦观察者和被观察者。策略模式跟两者类似,也能起到解耦的作用,不过,它解耦的是策略的定义、创建、使用这三部分。
1.策略的定义
策略类的定义比较简单,包含一个策略接口和一组实现这个接口的策略类。因为所有的策略类都实现相同的接口,所以,客户端代码基于接口而非实现编程,可以灵活地替换不同的策略。示例代码如下所示:
public interface Strategy {
void algorithmInterface();
}
public class ConcreteStrategyA implements Strategy {
@Override
public void algorithmInterface() {
//具体的算法...
}
}
public class ConcreteStrategyB implements Strategy {
@Override
public void algorithmInterface() {
//具体的算法...
}
}
2.策略的创建
因为策略模式会包含一组策略,在使用它们的时候,一般会通过类型(type)来判断创建哪个策略来使用。为了封装创建逻辑,我们需要对客户端代码屏蔽创建细节。我们可以把根据type创建策略的逻辑抽离出来,放到工厂类中。示例代码如下所示:
public class StrategyFactory {
private static final Map<String, Strategy> strategies = new HashMap<>();
static {
strategies.put("A", new ConcreteStrategyA());
strategies.put("B", new ConcreteStrategyB());
}
public static Strategy getStrategy(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
return strategies.get(type);
}
}
一般来讲,如果策略类是无状态的,不包含成员变量,只是纯粹的算法实现,这样的策略对象是可以被共享使用的,不需要在每次调用getStrategy()的时候,都创建一个新的策略对象。针对这种情况,我们可以使用上面这种工厂类的实现方式,事先创建好每个策略对象,缓存到工厂类中,用的时候直接返回。
相反,如果策略类是有状态的,根据业务场景的需要,我们希望每次从工厂方法中,获得的都是新创建的策略对象,而不是缓存好可共享的策略对象,那我们就需要按照如下方式来实现策略工厂类。
public class StrategyFactory {
public static Strategy getStrategy(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
if (type.equals("A")) {
return new ConcreteStrategyA();
} else if (type.equals("B")) {
return new ConcreteStrategyB();
}
return null;
}
}
3.策略的使用
策略模式包含一组可选策略,客户端代码一般如何确定使用哪个策略呢?最常见的是运行时动态确定使用哪种策略,这也是策略模式最典型的应用场景。
这里的“运行时动态”指的是,我们事先并不知道会使用哪个策略,而是在程序运行期间,根据配置、用户输入、计算结果等这些不确定因素,动态决定使用哪种策略。
// 策略接口:EvictionStrategy
// 策略类:LruEvictionStrategy、FifoEvictionStrategy、LfuEvictionStrategy...
// 策略工厂:EvictionStrategyFactory
public class UserCache {
private Map<String, User> cacheData = new HashMap<>();
private EvictionStrategy eviction;
public UserCache(EvictionStrategy eviction) {
this.eviction = eviction;
}
//...
}
// 运行时动态确定,根据配置文件的配置决定使用哪种策略
public class Application {
public static void main(String[] args) throws Exception {
EvictionStrategy evictionStrategy = null;
Properties props = new Properties();
props.load(new FileInputStream("./config.properties"));
String type = props.getProperty("eviction_type");
evictionStrategy = EvictionStrategyFactory.getEvictionStrategy(type);
UserCache userCache = new UserCache(evictionStrategy);
//...
}
}
// 非运行时动态确定,在代码中指定使用哪种策略
public class Application {
public static void main(String[] args) {
//...
EvictionStrategy evictionStrategy = new LruEvictionStrategy();
UserCache userCache = new UserCache(evictionStrategy);
//...
}
}
如何利用策略模式避免分支判断?
实际上,能够移除分支判断逻辑的模式不仅仅有策略模式,后面我们要讲的状态模式也可以。对于使用哪种模式,具体还要看应用场景来定。 策略模式适用于根据不同类型的动态,决定使用哪种策略这样一种应用场景。
我们先通过一个例子来看下,if-else或switch-case分支判断逻辑是如何产生的。具体的代码如下所示。在这个例子中,我们没有使用策略模式,而是将策略的定义、创建、使用直接耦合在一起。
public class OrderService {
public double discount(Order order) {
double discount = 0.0;
OrderType type = order.getType();
if (type.equals(OrderType.NORMAL)) { // 普通订单
//...省略折扣计算算法代码
} else if (type.equals(OrderType.GROUPON)) { // 团购订单
//...省略折扣计算算法代码
} else if (type.equals(OrderType.PROMOTION)) { // 促销订单
//...省略折扣计算算法代码
}
return discount;
}
}
如何来移除掉分支判断逻辑呢?那策略模式就派上用场了。我们使用策略模式对上面的代码重构,将不同类型订单的打折策略设计成策略类,并由工厂类来负责创建策略对象。具体的代码如下所示:
// 策略的定义
public interface DiscountStrategy {
double calDiscount(Order order);
}
// 省略NormalDiscountStrategy、GrouponDiscountStrategy、PromotionDiscountStrategy类代码...
// 策略的创建
public class DiscountStrategyFactory {
private static final Map<OrderType, DiscountStrategy> strategies = new HashMap<>();
static {
strategies.put(OrderType.NORMAL, new NormalDiscountStrategy());
strategies.put(OrderType.GROUPON, new GrouponDiscountStrategy());
strategies.put(OrderType.PROMOTION, new PromotionDiscountStrategy());
}
public static DiscountStrategy getDiscountStrategy(OrderType type) {
return strategies.get(type);
}
}
// 策略的使用
public class OrderService {
public double discount(Order order) {
OrderType type = order.getType();
DiscountStrategy discountStrategy = DiscountStrategyFactory.getDiscountStrategy(type);
return discountStrategy.calDiscount(order);
}
}
重构之后的代码就没有了if-else分支判断语句了。实际上,这得益于策略工厂类。在工厂类中,我们用Map来缓存策略,根据type直接从Map中获取对应的策略,从而避免if-else分支判断逻辑。等后面讲到使用状态模式来避免分支判断逻辑的时候,你会发现,它们使用的是同样的套路。本质上都是借助“查表法”,根据type查表(代码中的strategies就是表)替代根据type分支判断。
但是,如果业务场景需要每次都创建不同的策略对象,我们就要用另外一种工厂类的实现方式了。具体的代码如下所示:
public class DiscountStrategyFactory {
public static DiscountStrategy getDiscountStrategy(OrderType type) {
if (type == null) {
throw new IllegalArgumentException("Type should not be null.");
}
if (type.equals(OrderType.NORMAL)) {
return new NormalDiscountStrategy();
} else if (type.equals(OrderType.GROUPON)) {
return new GrouponDiscountStrategy();
} else if (type.equals(OrderType.PROMOTION)) {
return new PromotionDiscountStrategy();
}
return null;
}
}
这种实现方式相当于把原来的if-else分支逻辑,从OrderService类中转移到了工厂类中,实际上并没有真正将它移除。
例子:实现一个支持给不同大小文件排序的小程序
问题与解决思路
假设有这样一个需求,希望写一个小程序,实现对一个文件进行排序的功能。文件中只包含整型数,并且,相邻的数字通过逗号来区隔。
你可能会说,这不是很简单嘛,只需要将文件中的内容读取出来,并且通过逗号分割成一个一个的数字,放到内存数组中,然后编写某种排序算法(比如快排),或者直接使用编程语言提供的排序函数,对数组进行排序,最后再将数组中的数据写入文件就可以了。
但是,如果文件很大呢?比如有10GB大小,因为内存有限(比如只有8GB大小),我们没办法一次性加载文件中的所有数据到内存中,这个时候,我们就要利用外部排序算法了。
如果文件更大,比如有100GB大小,我们为了利用CPU多核的优势,可以在外部排序的基础之上进行优化,加入多线程并发排序的功能,这就有点类似“单机版”的MapReduce。
如果文件非常大,比如有1TB大小,即便是单机多线程排序,这也算很慢了。这个时候,我们可以使用真正的MapReduce框架,利用多机的处理能力,提高排序的效率。
代码实现与分析
先用最简单直接的方式将它实现出来。(下面的代码只给出了跟设计模式相关的骨架代码,并没有给出每种排序算法的具体代码实现。)
public class Sorter {
private static final long GB = 1000 * 1000 * 1000;
public void sortFile(String filePath) {
// 省略校验逻辑
File file = new File(filePath);
long fileSize = file.length();
if (fileSize < 6 * GB) { // [0, 6GB)
quickSort(filePath);
} else if (fileSize < 10 * GB) { // [6GB, 10GB)
externalSort(filePath);
} else if (fileSize < 100 * GB) { // [10GB, 100GB)
concurrentExternalSort(filePath);
} else { // [100GB, ~)
mapreduceSort(filePath);
}
}
private void quickSort(String filePath) {
// 快速排序
}
private void externalSort(String filePath) {
// 外部排序
}
private void concurrentExternalSort(String filePath) {
// 多线程外部排序
}
private void mapreduceSort(String filePath) {
// 利用MapReduce多机排序
}
}
public class SortingTool {
public static void main(String[] args) {
Sorter sorter = new Sorter();
sorter.sortFile(args[0]);
}
}
如果只是开发一个简单的工具,那上面的代码实现就足够了。毕竟,代码不多,后续修改、扩展的需求也不多,怎么写都不会导致代码不可维护。但是,如果是在开发一个大型项目,排序文件只是其中的一个功能模块,那就要在代码设计、代码质量上下点儿功夫了。只有每个小的功能模块都写好,整个项目的代码才能不差。
在代码中并没有给出每种排序算法的代码实现。实际上,每种排序算法的实现逻辑都比较复杂,代码行数都比较多。所有排序算法的代码实现都堆在Sorter一个类中,这就会导致这个类的代码很多。而在“编码规范”那一部分中也讲到,一个类的代码太多也会影响到可读性、可维护性。除此之外,所有的排序算法都设计成Sorter的私有函数,也会影响代码的可复用性。
代码优化与重构
只要掌握了我们之前讲过的设计原则和思想,针对上面的问题,即便想不到该用什么设计模式来重构,也应该能知道该如何解决,那就是将Sorter类中的某些代码拆分出来,独立成职责更加单一的小类。实际上,拆分是应对类或者函数代码过多、应对代码复杂性的一个常用手段。按照这个解决思路,对代码进行重构。
public interface ISortAlg {
void sort(String filePath);
}
public class QuickSort implements ISortAlg {
@Override
public void sort(String filePath) {
//...
}
}
public class ExternalSort implements ISortAlg {
@Override
public void sort(String filePath) {
//...
}
}
public class ConcurrentExternalSort implements ISortAlg {
@Override
public void sort(String filePath) {
//...
}
}
public class MapReduceSort implements ISortAlg {
@Override
public void sort(String filePath) {
//...
}
}
public class Sorter {
private static final long GB = 1000 * 1000 * 1000;
public void sortFile(String filePath) {
// 省略校验逻辑
File file = new File(filePath);
long fileSize = file.length();
ISortAlg sortAlg;
if (fileSize < 6 * GB) { // [0, 6GB)
sortAlg = new QuickSort();
} else if (fileSize < 10 * GB) { // [6GB, 10GB)
sortAlg = new ExternalSort();
} else if (fileSize < 100 * GB) { // [10GB, 100GB)
sortAlg = new ConcurrentExternalSort();
} else { // [100GB, ~)
sortAlg = new MapReduceSort();
}
sortAlg.sort(filePath);
}
}
经过拆分之后,每个类的代码都不会太多,每个类的逻辑都不会太复杂,代码的可读性、可维护性提高了。除此之外,将排序算法设计成独立的类,跟具体的业务逻辑(代码中的if-else那部分逻辑)解耦,也让排序算法能够复用。这一步实际上就是策略模式的第一步,也就是将策略的定义分离出来。
实际上,上面的代码还可以继续优化。每种排序类都是无状态的,我们没必要在每次使用的时候,都重新创建一个新的对象。所以,还可以使用工厂模式对对象的创建进行封装。
public class SortAlgFactory {
private static final Map<String, ISortAlg> algs = new HashMap<>();
static {
algs.put("QuickSort", new QuickSort());
algs.put("ExternalSort", new ExternalSort());
algs.put("ConcurrentExternalSort", new ConcurrentExternalSort());
algs.put("MapReduceSort", new MapReduceSort());
}
public static ISortAlg getSortAlg(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
return algs.get(type);
}
}
public class Sorter {
private static final long GB = 1000 * 1000 * 1000;
public void sortFile(String filePath) {
// 省略校验逻辑
File file = new File(filePath);
long fileSize = file.length();
ISortAlg sortAlg;
if (fileSize < 6 * GB) { // [0, 6GB)
sortAlg = SortAlgFactory.getSortAlg("QuickSort");
} else if (fileSize < 10 * GB) { // [6GB, 10GB)
sortAlg = SortAlgFactory.getSortAlg("ExternalSort");
} else if (fileSize < 100 * GB) { // [10GB, 100GB)
sortAlg = SortAlgFactory.getSortAlg("ConcurrentExternalSort");
} else { // [100GB, ~)
sortAlg = SortAlgFactory.getSortAlg("MapReduceSort");
}
sortAlg.sort(filePath);
}
}
经过上面两次重构之后,现在的代码实际上已经符合策略模式的代码结构了。我们通过策略模式将策略的定义、创建、使用解耦,让每一部分都不至于太复杂。不过,Sorter类中的sortFile()函数还是有一堆if-else逻辑。这里的if-else逻辑分支不多、也不复杂,这样写完全没问题。但如果想将if-else分支判断移除掉,那也是有办法的。
public class Sorter {
private static final long GB = 1000 * 1000 * 1000;
private static final List<AlgRange> algs = new ArrayList<>();
static {
algs.add(new AlgRange(0, 6*GB, SortAlgFactory.getSortAlg("QuickSort")));
algs.add(new AlgRange(6*GB, 10*GB, SortAlgFactory.getSortAlg("ExternalSort")));
algs.add(new AlgRange(10*GB, 100*GB, SortAlgFactory.getSortAlg("ConcurrentExternalSort")));
algs.add(new AlgRange(100*GB, Long.MAX_VALUE, SortAlgFactory.getSortAlg("MapReduceSort")));
}
public void sortFile(String filePath) {
// 省略校验逻辑
File file = new File(filePath);
long fileSize = file.length();
ISortAlg sortAlg = null;
for (AlgRange algRange : algs) {
if (algRange.inRange(fileSize)) {
sortAlg = algRange.getAlg();
break;
}
}
sortAlg.sort(filePath);
}
private static class AlgRange {
private long start;
private long end;
private ISortAlg alg;
public AlgRange(long start, long end, ISortAlg alg) {
this.start = start;
this.end = end;
this.alg = alg;
}
public ISortAlg getAlg() {
return alg;
}
public boolean inRange(long size) {
return size >= start && size < end;
}
}
}
实际上,这也是基于查表法来解决的,其中的“algs”就是“表”。
现在的代码实现就更加优美了。我们把可变的部分隔离到了策略工厂类和Sorter类中的静态代码段中。当要添加一个新的排序算法时,只需要修改策略工厂类和Sort类中的静态代码段,其他代码都不需要修改,这样就将代码改动最小化、集中化了。
你可能会说,即便这样,当我们添加新的排序算法的时候,还是需要修改代码,并不完全符合开闭原则。有什么办法让我们完全满足开闭原则呢?
对于Java语言来说,我们可以通过反射来避免对策略工厂类的修改。具体是这么做的:我们通过一个配置文件或者自定义的annotation来标注都有哪些策略类;策略工厂类读取配置文件或者搜索被annotation标注的策略类,然后通过反射动态地加载这些策略类、创建策略对象;当我们新添加一个策略的时候,只需要将这个新添加的策略类添加到配置文件或者用annotation标注即可。
对于Sorter来说,我们可以通过同样的方法来避免修改。我们通过将文件大小区间和算法之间的对应关系放到配置文件中。当添加新的排序算法时,我们只需要改动配置文件即可,不需要改动代码。
职责链模式
职责链模式的原理和实现
职责链模式的英文翻译是Chain Of Responsibility Design Pattern。在GoF的《设计模式》中,它是这么定义的:
Avoid coupling the sender of a request to its receiver by giving more than one object a chance to handle the request. Chain the receiving objects and pass the request along the chain until an object handles it.
翻译成中文就是:将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。
这么说比较抽象,我用更加容易理解的话来进一步解读一下。
在职责链模式中,多个处理器(也就是刚刚定义中说的“接收对象”)依次处理同一个请求。一个请求先经过A处理器处理,然后再把请求传递给B处理器,B处理器处理完后再传递给C处理器,以此类推,形成一个链条。链条上的每个处理器各自承担各自的处理职责,所以叫作职责链模式。
职责链模式有多种实现方式,第一种实现方式如下所示。其中,Handler是所有处理器类的抽象父类,handle()是抽象方法。每个具体的处理器类(HandlerA、HandlerB)的handle()函数的代码结构类似,如果它能处理该请求,就不继续往下传递;如果不能处理,则交由后面的处理器来处理(也就是调用successor.handle())。HandlerChain是处理器链,从数据结构的角度来看,它就是一个记录了链头、链尾的链表。其中,记录链尾是为了方便添加处理器。
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public abstract void handle();
}
public class HandlerA extends Handler {
@Override
public void handle() {
boolean handled = false;
//...
if (!handled && successor != null) {
successor.handle();
}
}
}
public class HandlerB extends Handler {
@Override
public void handle() {
boolean handled = false;
//...
if (!handled && successor != null) {
successor.handle();
}
}
}
public class HandlerChain {
private Handler head = null;
private Handler tail = null;
public void addHandler(Handler handler) {
handler.setSuccessor(null);
if (head == null) {
head = handler;
tail = handler;
return;
}
tail.setSuccessor(handler);
tail = handler;
}
public void handle() {
if (head != null) {
head.handle();
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}
实际上,上面的代码实现不够优雅。处理器类的handle()函数,不仅包含自己的业务逻辑,还包含对下一个处理器的调用,也就是代码中的successor.handle()。一个不熟悉这种代码结构的程序员,在添加新的处理器类的时候,很有可能忘记在handle()函数中调用successor.handle(),这就会导致代码出现bug。
针对这个问题,我们对代码进行重构,利用模板模式,将调用successor.handle()的逻辑从具体的处理器类中剥离出来,放到抽象父类中。这样具体的处理器类只需要实现自己的业务逻辑就可以了。重构之后的代码如下所示:
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public final void handle() {
boolean handled = doHandle();
if (successor != null && !handled) {
successor.handle();
}
}
protected abstract boolean doHandle();
}
public class HandlerA extends Handler {
@Override
protected boolean doHandle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerB extends Handler {
@Override
protected boolean doHandle() {
boolean handled = false;
//...
return handled;
}
}
// HandlerChain和Application代码不变
再来看第二种实现方式,代码如下所示。这种实现方式更加简单。HandlerChain类用数组而非链表来保存所有的处理器,并且需要在HandlerChain的handle()函数中,依次调用每个处理器的handle()函数。
public interface IHandler {
boolean handle();
}
public class HandlerA implements IHandler {
@Override
public boolean handle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerB implements IHandler {
@Override
public boolean handle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerChain {
private List<IHandler> handlers = new ArrayList<>();
public void addHandler(IHandler handler) {
this.handlers.add(handler);
}
public void handle() {
for (IHandler handler : handlers) {
boolean handled = handler.handle();
if (handled) {
break;
}
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}
在GoF给出的定义中,如果处理器链上的某个处理器能够处理这个请求,那就不会继续往下传递请求。实际上,职责链模式还有一种变体,那就是请求会被所有的处理器都处理一遍,不存在中途终止的情况。这种变体也有两种实现方式:用链表存储处理器和用数组存储处理器,跟上面的两种实现方式类似,只需要稍微修改即可。
职责链模式的应用场景举例
敏感词过滤
对于支持UGC(User Generated Content,用户生成内容)的应用(比如论坛)来说,用户生成的内容(比如,在论坛中发表的帖子)可能会包含一些敏感词(比如涉黄、广告、反动等词汇)。针对这个应用场景,我们就可以利用职责链模式来过滤这些敏感词。
对于包含敏感词的内容,我们有两种处理方式,一种是直接禁止发布,另一种是给敏感词打马赛克(比如,用***替换敏感词)之后再发布。第一种处理方式符合GoF给出的职责链模式的定义,第二种处理方式是职责链模式的变体。
这里只给出第一种实现方式的代码示例,如下所示,并且,我们只给出了代码实现的骨架,具体的敏感词过滤算法并没有给出。
public interface SensitiveWordFilter {
boolean doFilter(Content content);
}
public class SexyWordFilter implements SensitiveWordFilter {
@Override
public boolean doFilter(Content content) {
boolean legal = true;
//...
return legal;
}
}
// PoliticalWordFilter、AdsWordFilter类代码结构与SexyWordFilter类似
public class SensitiveWordFilterChain {
private List<SensitiveWordFilter> filters = new ArrayList<>();
public void addFilter(SensitiveWordFilter filter) {
this.filters.add(filter);
}
// return true if content doesn't contain sensitive words.
public boolean filter(Content content) {
for (SensitiveWordFilter filter : filters) {
if (!filter.doFilter(content)) {
return false;
}
}
return true;
}
}
public class ApplicationDemo {
public static void main(String[] args) {
SensitiveWordFilterChain filterChain = new SensitiveWordFilterChain();
filterChain.addFilter(new AdsWordFilter());
filterChain.addFilter(new SexyWordFilter());
filterChain.addFilter(new PoliticalWordFilter());
boolean legal = filterChain.filter(new Content());
if (!legal) {
// 不发表
} else {
// 发表
}
}
}
Servlet Filter
Servlet Filter是Java Servlet规范中定义的组件,翻译成中文就是过滤器,它可以实现对HTTP请求的过滤功能,比如鉴权、限流、记录日志、验证参数等等。因为它是Servlet规范的一部分,所以,只要是支持Servlet的Web容器(比如,Tomcat、Jetty等),都支持过滤器功能。
在实际项目中,要使用Servlet Filter,只需要定义一个实现javax.servlet.Filter接口的过滤器类,并且将它配置在web.xml配置文件中。Web容器启动的时候,会读取web.xml中的配置,创建过滤器对象。当有请求到来的时候,会先经过过滤器,然后才由Servlet来处理。
public class LogFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
// 在创建Filter时自动调用,
// 其中filterConfig包含这个Filter的配置参数,比如name之类的(从配置文件中读取的)
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("拦截客户端发送来的请求.");
chain.doFilter(request, response);
System.out.println("拦截发送给客户端的响应.");
}
@Override
public void destroy() {
// 在销毁Filter时自动调用
}
}
// 在web.xml配置文件中如下配置:
<filter>
<filter-name>logFilter</filter-name>
<filter-class>com.xzg.cd.LogFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>logFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
职责链模式的实现包含处理器接口(IHandler)或抽象类(Handler),以及处理器链(HandlerChain)。对应到Servlet Filter,javax.servlet.Filter就是处理器接口,FilterChain就是处理器链。
不过,Servlet只是一个规范,并不包含具体的实现,所以,Servlet中的FilterChain只是一个接口定义。具体的实现类由遵从Servlet规范的Web容器来提供,比如,ApplicationFilterChain类就是Tomcat提供的FilterChain的实现类,源码(简化后)如下所示。
public final class ApplicationFilterChain implements FilterChain {
private int pos = 0; //当前执行到了哪个filter
private int n; //filter的个数
private ApplicationFilterConfig[] filters;
private Servlet servlet;
@Override
public void doFilter(ServletRequest request, ServletResponse response) {
if (pos < n) {
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
filter.doFilter(request, response, this);
} else {
// filter都处理完毕后,执行servlet
servlet.service(request, response);
}
}
public void addFilter(ApplicationFilterConfig filterConfig) {
for (ApplicationFilterConfig filter:filters)
if (filter==filterConfig)
return;
if (n == filters.length) {//扩容
ApplicationFilterConfig[] newFilters = new ApplicationFilterConfig[n + INCREMENT];
System.arraycopy(filters, 0, newFilters, 0, n);
filters = newFilters;
}
filters[n++] = filterConfig;
}
}
ApplicationFilterChain中的doFilter()函数的代码实现比较有技巧,实际上是一个递归调用。你可以用每个Filter(比如LogFilter)的doFilter()的代码实现,直接替换ApplicationFilterChain的第12行代码,一眼就能看出是递归调用了。
这样实现主要是为了在一个doFilter()方法中,支持双向拦截,既能拦截客户端发送来的请求,也能拦截发送给客户端的响应。
Spring Interceptor
Spring Interceptor,翻译成中文就是拦截器。尽管英文单词和中文翻译都不同,但这两者基本上可以看作一个概念,都用来实现对HTTP请求进行拦截处理。
它们不同之处在于,Servlet Filter是Servlet规范的一部分,实现依赖于Web容器。Spring Interceptor是Spring MVC框架的一部分,由Spring MVC框架来提供实现。客户端发送的请求,会先经过Servlet Filter,然后再经过Spring Interceptor,最后到达具体的业务代码中。
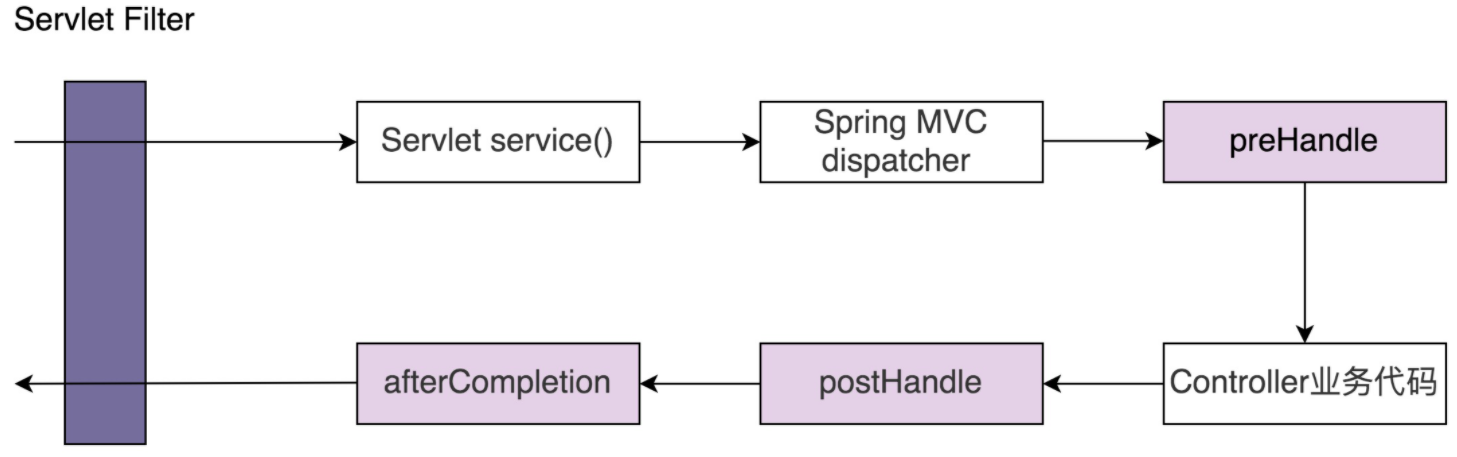
在项目中,该如何使用Spring Interceptor呢?一个简单的示例代码,如下所示。LogInterceptor实现的功能跟刚才的LogFilter完全相同,只是实现方式上稍有区别。LogFilter对请求和响应的拦截是在doFilter()一个函数中实现的,而LogInterceptor对请求的拦截在preHandle()中实现,对响应的拦截在postHandle()中实现。
public class LogInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("拦截客户端发送来的请求.");
return true; // 继续后续的处理
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("拦截发送给客户端的响应.");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("这里总是被执行.");
}
}
//在Spring MVC配置文件中配置interceptors
<mvc:interceptors>
<mvc:interceptor>
<mvc:mapping path="/*"/>
<bean class="com.xzg.cd.LogInterceptor" />
</mvc:interceptor>
</mvc:interceptors>
Spring Interceptor底层也是基于职责链模式实现的。其中,HandlerExecutionChain类是职责链模式中的处理器链。它的实现相较于Tomcat中的ApplicationFilterChain来说,逻辑更加清晰,不需要使用递归来实现,主要是因为它将请求和响应的拦截工作,拆分到了两个函数中实现。HandlerExecutionChain的源码(简化)如下所示:
public class HandlerExecutionChain {
private final Object handler;
private HandlerInterceptor[] interceptors;
public void addInterceptor(HandlerInterceptor interceptor) {
initInterceptorList().add(interceptor);
}
boolean applyPreHandle(HttpServletRequest request, HttpServletResponse response) throws Exception {
HandlerInterceptor[] interceptors = getInterceptors();
if (!ObjectUtils.isEmpty(interceptors)) {
for (int i = 0; i < interceptors.length; i++) {
HandlerInterceptor interceptor = interceptors[i];
if (!interceptor.preHandle(request, response, this.handler)) {
triggerAfterCompletion(request, response, null);
return false;
}
}
}
return true;
}
void applyPostHandle(HttpServletRequest request, HttpServletResponse response, ModelAndView mv) throws Exception {
HandlerInterceptor[] interceptors = getInterceptors();
if (!ObjectUtils.isEmpty(interceptors)) {
for (int i = interceptors.length - 1; i >= 0; i--) {
HandlerInterceptor interceptor = interceptors[i];
interceptor.postHandle(request, response, this.handler, mv);
}
}
}
void triggerAfterCompletion(HttpServletRequest request, HttpServletResponse response, Exception ex)
throws Exception {
HandlerInterceptor[] interceptors = getInterceptors();
if (!ObjectUtils.isEmpty(interceptors)) {
for (int i = this.interceptorIndex; i >= 0; i--) {
HandlerInterceptor interceptor = interceptors[i];
try {
interceptor.afterCompletion(request, response, this.handler, ex);
} catch (Throwable ex2) {
logger.error("HandlerInterceptor.afterCompletion threw exception", ex2);
}
}
}
}
}
在Spring框架中,DispatcherServlet的doDispatch()方法来分发请求,它在真正的业务逻辑执行前后,执行HandlerExecutionChain中的applyPreHandle()和applyPostHandle()函数,用来实现拦截的功能。
状态模式
有限状态机
有限状态机,Finite State Machine,缩写为FSM,简称为状态机。状态机有3个组成部分:状态(State)、事件(Event)、动作(Action)。其中,事件也称为转移条件(Transition Condition)。事件触发状态的转移及动作的执行。不过,动作不是必须的,也可能只转移状态,不执行任何动作。
在“超级马里奥”游戏中,马里奥可以变身为多种形态,比如小马里奥(Small Mario)、超级马里奥(Super Mario)、火焰马里奥(Fire Mario)、斗篷马里奥(Cape Mario)等等。在不同的游戏情节下,各个形态会互相转化,并相应的增减积分。比如,初始形态是小马里奥,吃了蘑菇之后就会变成超级马里奥,并且增加100积分。
实际上,马里奥形态的转变就是一个状态机。其中,马里奥的不同形态就是状态机中的“状态”,游戏情节(比如吃了蘑菇)就是状态机中的“事件”,加减积分就是状态机中的“动作”。比如,吃蘑菇这个事件,会触发状态的转移:从小马里奥转移到超级马里奥,以及触发动作的执行(增加100积分)。
如何将上面的状态转移图翻译成代码呢?
骨架代码,如下所示。其中,obtainMushRoom()、obtainCape()、obtainFireFlower()、meetMonster()这几个函数,能够根据当前的状态和事件,更新状态和增减积分。
public enum State {
SMALL(0),
SUPER(1),
FIRE(2),
CAPE(3);
private int value;
private State(int value) {
this.value = value;
}
public int getValue() {
return this.value;
}
}
public class MarioStateMachine {
private int score;
private State currentState;
public MarioStateMachine() {
this.score = 0;
this.currentState = State.SMALL;
}
public void obtainMushRoom() {
//TODO
}
public void obtainCape() {
//TODO
}
public void obtainFireFlower() {
//TODO
}
public void meetMonster() {
//TODO
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState;
}
}
public class ApplicationDemo {
public static void main(String[] args) {
MarioStateMachine mario = new MarioStateMachine();
mario.obtainMushRoom();
int score = mario.getScore();
State state = mario.getCurrentState();
System.out.println("mario score: " + score + "; state: " + state);
}
}
状态机实现方式一:分支逻辑法
public class MarioStateMachine {
private int score;
private State currentState;
public MarioStateMachine() {
this.score = 0;
this.currentState = State.SMALL;
}
public void obtainMushRoom() {
if (currentState.equals(State.SMALL)) {
this.currentState = State.SUPER;
this.score += 100;
}
}
public void obtainCape() {
if (currentState.equals(State.SMALL) || currentState.equals(State.SUPER) ) {
this.currentState = State.CAPE;
this.score += 200;
}
}
public void obtainFireFlower() {
if (currentState.equals(State.SMALL) || currentState.equals(State.SUPER) ) {
this.currentState = State.FIRE;
this.score += 300;
}
}
public void meetMonster() {
if (currentState.equals(State.SUPER)) {
this.currentState = State.SMALL;
this.score -= 100;
return;
}
if (currentState.equals(State.CAPE)) {
this.currentState = State.SMALL;
this.score -= 200;
return;
}
if (currentState.equals(State.FIRE)) {
this.currentState = State.SMALL;
this.score -= 300;
return;
}
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState;
}
}
对于简单的状态机来说,分支逻辑这种实现方式是可以接受的。但是,对于复杂的状态机来说,这种实现方式极易漏写或者错写某个状态转移。除此之外,代码中充斥着大量的if-else或者switch-case分支判断逻辑,可读性和可维护性都很差。如果哪天修改了状态机中的某个状态转移,我们要在冗长的分支逻辑中找到对应的代码进行修改,很容易改错,引入bug。
状态机实现方式二:查表法
实际上,上面这种实现方法有点类似hard code,对于复杂的状态机来说不适用,而状态机的第二种实现方式查表法,就更加合适了。
实际上,除了用状态转移图来表示之外,状态机还可以用二维表来表示,如下所示。在这个二维表中,第一维表示当前状态,第二维表示事件,值表示当前状态经过事件之后,转移到的新状态及其执行的动作。
相对于分支逻辑的实现方式,查表法的代码实现更加清晰,可读性和可维护性更好。当修改状态机时,我们只需要修改transitionTable和actionTable两个二维数组即可。实际上,如果我们把这两个二维数组存储在配置文件中,当需要修改状态机时,我们甚至可以不修改任何代码,只需要修改配置文件就可以了。具体的代码如下所示:
public enum Event {
GOT_MUSHROOM(0),
GOT_CAPE(1),
GOT_FIRE(2),
MET_MONSTER(3);
private int value;
private Event(int value) {
this.value = value;
}
public int getValue() {
return this.value;
}
}
public class MarioStateMachine {
private int score;
private State currentState;
private static final State[][] transitionTable = {
{SUPER, CAPE, FIRE, SMALL},
{SUPER, CAPE, FIRE, SMALL},
{CAPE, CAPE, CAPE, SMALL},
{FIRE, FIRE, FIRE, SMALL}
};
private static final int[][] actionTable = {
{+100, +200, +300, +0},
{+0, +200, +300, -100},
{+0, +0, +0, -200},
{+0, +0, +0, -300}
};
public MarioStateMachine() {
this.score = 0;
this.currentState = State.SMALL;
}
public void obtainMushRoom() {
executeEvent(Event.GOT_MUSHROOM);
}
public void obtainCape() {
executeEvent(Event.GOT_CAPE);
}
public void obtainFireFlower() {
executeEvent(Event.GOT_FIRE);
}
public void meetMonster() {
executeEvent(Event.MET_MONSTER);
}
private void executeEvent(Event event) {
int stateValue = currentState.getValue();
int eventValue = event.getValue();
this.currentState = transitionTable[stateValue][eventValue];
this.score += actionTable[stateValue][eventValue];
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState;
}
}
状态机实现方式三:状态模式
在查表法的代码实现中,事件触发的动作只是简单的积分加减,所以,用一个int类型的二维数组actionTable就能表示,二维数组中的值表示积分的加减值。但是,如果要执行的动作并非这么简单,而是一系列复杂的逻辑操作(比如加减积分、写数据库,还有可能发送消息通知等等),就没法用如此简单的二维数组来表示了。这也就是说,查表法的实现方式有一定局限性。
虽然分支逻辑的实现方式不存在这个问题,但它又存在前面讲到的其他问题,比如分支判断逻辑较多,导致代码可读性和可维护性不好等。实际上,针对分支逻辑法存在的问题,我们可以使用状态模式来解决。
状态模式通过将事件触发的状态转移和动作执行,拆分到不同的状态类中,来避免分支判断逻辑。
利用状态模式来补全MarioStateMachine类,补全后的代码如下所示。
其中,IMario是状态的接口,定义了所有的事件。SmallMario、SuperMario、CapeMario、FireMario是IMario接口的实现类,分别对应状态机中的4个状态。原来所有的状态转移和动作执行的代码逻辑,都集中在MarioStateMachine类中,现在,这些代码逻辑被分散到了这4个状态类中。
public interface IMario { //所有状态类的接口
State getName();
//以下是定义的事件
void obtainMushRoom();
void obtainCape();
void obtainFireFlower();
void meetMonster();
}
public class SmallMario implements IMario {
private MarioStateMachine stateMachine;
public SmallMario(MarioStateMachine stateMachine) {
this.stateMachine = stateMachine;
}
@Override
public State getName() {
return State.SMALL;
}
@Override
public void obtainMushRoom() {
stateMachine.setCurrentState(new SuperMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 100);
}
@Override
public void obtainCape() {
stateMachine.setCurrentState(new CapeMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 200);
}
@Override
public void obtainFireFlower() {
stateMachine.setCurrentState(new FireMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 300);
}
@Override
public void meetMonster() {
// do nothing...
}
}
public class SuperMario implements IMario {
private MarioStateMachine stateMachine;
public SuperMario(MarioStateMachine stateMachine) {
this.stateMachine = stateMachine;
}
@Override
public State getName() {
return State.SUPER;
}
@Override
public void obtainMushRoom() {
// do nothing...
}
@Override
public void obtainCape() {
stateMachine.setCurrentState(new CapeMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 200);
}
@Override
public void obtainFireFlower() {
stateMachine.setCurrentState(new FireMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 300);
}
@Override
public void meetMonster() {
stateMachine.setCurrentState(new SmallMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() - 100);
}
}
// 省略CapeMario、FireMario类...
public class MarioStateMachine {
private int score;
private IMario currentState; // 不再使用枚举来表示状态
public MarioStateMachine() {
this.score = 0;
this.currentState = new SmallMario(this);
}
public void obtainMushRoom() {
this.currentState.obtainMushRoom();
}
public void obtainCape() {
this.currentState.obtainCape();
}
public void obtainFireFlower() {
this.currentState.obtainFireFlower();
}
public void meetMonster() {
this.currentState.meetMonster();
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState.getName();
}
public void setScore(int score) {
this.score = score;
}
public void setCurrentState(IMario currentState) {
this.currentState = currentState;
}
}
需要强调的是,MarioStateMachine和各个状态类之间是双向依赖关系。MarioStateMachine依赖各个状态类是理所当然的,但是,反过来,各个状态类为什么要依赖MarioStateMachine呢?这是因为,各个状态类需要更新MarioStateMachine中的两个变量,score和currentState。
实际上,上面的代码还可以继续优化,我们可以将状态类设计成单例,毕竟状态类中不包含任何成员变量。但是,当将状态类设计成单例之后,我们就无法通过构造函数来传递MarioStateMachine了,而状态类又要依赖MarioStateMachine。
前面单例模式的章节中提到过几种解决方法,在这里,我们可以通过函数参数将MarioStateMachine传递进状态类。
public interface IMario {
State getName();
void obtainMushRoom(MarioStateMachine stateMachine);
void obtainCape(MarioStateMachine stateMachine);
void obtainFireFlower(MarioStateMachine stateMachine);
void meetMonster(MarioStateMachine stateMachine);
}
public class SmallMario implements IMario {
private static final SmallMario instance = new SmallMario();
private SmallMario() {}
public static SmallMario getInstance() {
return instance;
}
@Override
public State getName() {
return State.SMALL;
}
@Override
public void obtainMushRoom(MarioStateMachine stateMachine) {
stateMachine.setCurrentState(SuperMario.getInstance());
stateMachine.setScore(stateMachine.getScore() + 100);
}
@Override
public void obtainCape(MarioStateMachine stateMachine) {
stateMachine.setCurrentState(CapeMario.getInstance());
stateMachine.setScore(stateMachine.getScore() + 200);
}
@Override
public void obtainFireFlower(MarioStateMachine stateMachine) {
stateMachine.setCurrentState(FireMario.getInstance());
stateMachine.setScore(stateMachine.getScore() + 300);
}
@Override
public void meetMonster(MarioStateMachine stateMachine) {
// do nothing...
}
}
// 省略SuperMario、CapeMario、FireMario类...
public class MarioStateMachine {
private int score;
private IMario currentState;
public MarioStateMachine() {
this.score = 0;
this.currentState = SmallMario.getInstance();
}
public void obtainMushRoom() {
this.currentState.obtainMushRoom(this);
}
public void obtainCape() {
this.currentState.obtainCape(this);
}
public void obtainFireFlower() {
this.currentState.obtainFireFlower(this);
}
public void meetMonster() {
this.currentState.meetMonster(this);
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState.getName();
}
public void setScore(int score) {
this.score = score;
}
public void setCurrentState(IMario currentState) {
this.currentState = currentState;
}
}
实际上,像游戏这种比较复杂的状态机,包含的状态比较多,我优先推荐使用查表法,而状态模式会引入非常多的状态类,会导致代码比较难维护。相反,像电商下单、外卖下单这种类型的状态机,它们的状态并不多,状态转移也比较简单,但事件触发执行的动作包含的业务逻辑可能会比较复杂,所以,更加推荐使用状态模式来实现。
迭代器模式
迭代器模式的原理和实现
迭代器模式(Iterator Design Pattern),也叫作游标模式(Cursor Design Pattern),用来遍历集合对象。这里说的“集合对象”也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如数组、链表、树、图、跳表。迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一。
迭代器是用来遍历容器的,所以,一个完整的迭代器模式一般会涉及容器和容器迭代器两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。
现在针对ArrayList和LinkedList两个线性容器,设计实现对应的迭代器。按照之前给出的迭代器模式的类图,定义一个迭代器接口Iterator,以及针对两种容器的具体的迭代器实现类ArrayIterator和ListIterator。先来看下Iterator接口的定义。
// 接口定义方式一
public interface Iterator<E> {
boolean hasNext();
void next();
E currentItem();
}
// 接口定义方式二
public interface Iterator<E> {
boolean hasNext();
E next();
}
Iterator接口有两种定义方式。
在第一种定义中,next()函数用来将游标后移一位元素,currentItem()函数用来返回当前游标指向的元素。在第二种定义中,返回当前元素与后移一位这两个操作,要放到同一个函数next()中完成。
第一种定义方式更加灵活一些,比如可以多次调用currentItem()查询当前元素,而不移动游标。
在接下来的实现中,选择了第一种接口定义方式。
public class ArrayIterator<E> implements Iterator<E> {
private int cursor;
private ArrayList<E> arrayList;
public ArrayIterator(ArrayList<E> arrayList) {
this.cursor = 0;
this.arrayList = arrayList;
}
@Override
public boolean hasNext() {
return cursor != arrayList.size(); //注意这里,cursor在指向最后一个元素的时候,hasNext()仍旧返回true。
}
@Override
public void next() {
cursor++;
}
@Override
public E currentItem() {
if (cursor >= arrayList.size()) {
throw new NoSuchElementException();
}
return arrayList.get(cursor);
}
}
public class Demo {
public static void main(String[] args) {
ArrayList<String> names = new ArrayList<>();
names.add("xzg");
names.add("wang");
names.add("zheng");
Iterator<String> iterator = new ArrayIterator(names);
while (iterator.hasNext()) {
System.out.println(iterator.currentItem());
iterator.next();
}
}
}
在上面的代码实现中,需要将待遍历的容器对象,通过构造函数传递给迭代器类。实际上,为了封装迭代器的创建细节,可以在容器中定义一个iterator()方法,来创建对应的迭代器。为了能实现基于接口而非实现编程,还需要将这个方法定义在List接口中。具体的代码实现和使用示例如下所示:
public interface List<E> {
Iterator iterator();
//...省略其他接口函数...
}
public class ArrayList<E> implements List<E> {
//...
public Iterator iterator() {
return new ArrayIterator(this);
}
//...省略其他代码
}
public class Demo {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("xzg");
names.add("wang");
names.add("zheng");
Iterator<String> iterator = names.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.currentItem());
iterator.next();
}
}
}
迭代器模式的优势
一般来讲,遍历集合数据有三种方法:for循环、foreach循环、iterator迭代器。
List<String> names = new ArrayList<>();
names.add("xzg");
names.add("wang");
names.add("zheng");
// 第一种遍历方式:for循环
for (int i = 0; i < names.size(); i++) {
System.out.print(names.get(i) + ",");
}
// 第二种遍历方式:foreach循环
for (String name : names) {
System.out.print(name + ",")
}
// 第三种遍历方式:迭代器遍历
Iterator<String> iterator = names.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + ",");//Java中的迭代器接口是第二种定义方式,next()既移动游标又返回数据
}
实际上,foreach循环只是一个语法糖而已,底层是基于迭代器来实现的。也就是说,上面代码中的第二种遍历方式(foreach循环代码)的底层实现,就是第三种遍历方式(迭代器遍历代码)。这两种遍历方式可以看作同一种遍历方式,也就是迭代器遍历方式。
从上面的代码来看,for循环遍历方式比起迭代器遍历方式,代码看起来更加简洁。那我们为什么还要用迭代器来遍历容器呢?为什么还要给容器设计对应的迭代器呢?原因有以下三个。
首先,对于类似数组和链表这样的数据结构,遍历方式比较简单,直接使用for循环来遍历就足够了。但是,对于复杂的数据结构(比如树、图)来说,有各种复杂的遍历方式。比如,树有前中后序、按层遍历,图有深度优先、广度优先遍历等等。如果由客户端代码来实现这些遍历算法,势必增加开发成本,而且容易写错。如果将这部分遍历的逻辑写到容器类中,也会导致容器类代码的复杂性。
前面也多次提到,应对复杂性的方法就是拆分。可以将遍历操作拆分到迭代器类中。比如,针对图的遍历,就可以定义DFSIterator、BFSIterator两个迭代器类,让它们分别来实现深度优先遍历和广度优先遍历。
其次,将游标指向的当前位置等信息,存储在迭代器类中,每个迭代器独享游标信息。这样就可以创建多个不同的迭代器,同时对同一个容器进行遍历而互不影响。
最后,容器和迭代器都提供了抽象的接口,方便在开发的时候,基于接口而非具体的实现编程。当需要切换新的遍历算法的时候,比如,从前往后遍历链表切换成从后往前遍历链表,客户端代码只需要将迭代器类从LinkedIterator切换为ReversedLinkedIterator即可,其他代码都不需要修改。除此之外,添加新的遍历算法,只需要扩展新的迭代器类,也更符合开闭原则。
在遍历的同时增删集合元素会发生什么?
在通过迭代器来遍历集合元素的同时,增加或者删除集合中的元素,有可能会导致某个元素被重复遍历或遍历不到。不过,并不是所有情况下都会遍历出错,有的时候也可以正常遍历,所以,这种行为称为结果不可预期行为或者未决行为,也就是说,运行结果到底是对还是错,要视情况而定。
如何应对遍历时改变集合导致的未决行为?
当通过迭代器来遍历集合的时候,增加、删除集合元素会导致不可预期的遍历结果。实际上,“不可预期”比直接出错更加可怕,有的时候运行正确,有的时候运行错误,一些隐藏很深、很难debug的bug就是这么产生的。那我们如何才能避免出现这种不可预期的运行结果呢?
有两种比较干脆利索的解决方案:一种是遍历的时候不允许增删元素,另一种是增删元素之后让遍历报错。
实际上,第一种解决方案比较难实现,我们要确定遍历开始和结束的时间点。遍历开始的时间节点我们很容易获得。我们可以把创建迭代器的时间点作为遍历开始的时间点。但是遍历结束的时间点比较难确定。所以第二种解决方法更加合理。
如何设计实现一个支持“快照”功能的iterator
理解这个问题最关键的是理解“快照”两个字。所谓“快照”,指我们为容器创建迭代器的时候,相当于给容器拍了一张快照(Snapshot)。之后即便我们增删容器中的元素,快照中的元素并不会做相应的改动。而迭代器遍历的对象是快照而非容器,这样就避免了在使用迭代器遍历的过程中,增删容器中的元素,导致的不可预期的结果或者报错。
List<Integer> list = new ArrayList<>();
list.add(3);
list.add(8);
list.add(2);
Iterator<Integer> iter1 = list.iterator();//snapshot: 3, 8, 2
list.remove(new Integer(2));//list:3, 8
Iterator<Integer> iter2 = list.iterator();//snapshot: 3, 8
list.remove(new Integer(3));//list:8
Iterator<Integer> iter3 = list.iterator();//snapshot: 3
// 输出结果:3 8 2
while (iter1.hasNext()) {
System.out.print(iter1.next() + " ");
}
System.out.println();
// 输出结果:3 8
while (iter2.hasNext()) {
System.out.print(iter1.next() + " ");
}
System.out.println();
// 输出结果:8
while (iter3.hasNext()) {
System.out.print(iter1.next() + " ");
}
System.out.println();
下面是针对这个功能需求的骨架代码,其中包含ArrayList、SnapshotArrayIterator两个类。
public ArrayList<E> implements List<E> {
// TODO: 成员变量、私有函数定义
@Override
public void add(E obj) {
//TODO
}
@Override
public void remove(E obj) {
// TODO
}
@Override
public Iterator<E> iterator() {
return new SnapshotArrayIterator(this);
}
}
public class SnapshotArrayIterator<E> implements Iterator<E> {
// TODO
@Override
public boolean hasNext() {
// TODO
}
@Override
public E next() {//返回当前元素,并且游标后移一位
// TODO
}
}
解决方案一
先来看最简单的一种解决办法。在迭代器类中定义一个成员变量snapshot来存储快照。每当创建迭代器的时候,都拷贝一份容器中的元素到快照中,后续的遍历操作都基于这个迭代器自己持有的快照来进行。
public class SnapshotArrayIterator<E> implements Iterator<E> {
private int cursor;
private ArrayList<E> snapshot;
public SnapshotArrayIterator(ArrayList<E> arrayList) {
this.cursor = 0;
this.snapshot = new ArrayList<>();
this.snapshot.addAll(arrayList);
}
@Override
public boolean hasNext() {
return cursor < snapshot.size();
}
@Override
public E next() {
E currentItem = snapshot.get(cursor);
cursor++;
return currentItem;
}
}
这个解决方案虽然简单,但代价也有点高。每次创建迭代器的时候,都要拷贝一份数据到快照中,会增加内存的消耗。如果一个容器同时有多个迭代器在遍历元素,就会导致数据在内存中重复存储多份。不过,庆幸的是,Java中的拷贝属于浅拷贝,也就是说,容器中的对象并非真的拷贝了多份,而只是拷贝了对象的引用而已。
解决方案二
可以在容器中,为每个元素保存两个时间戳,一个是添加时间戳addTimestamp,一个是删除时间戳delTimestamp。当元素被加入到集合中的时候,我们将addTimestamp设置为当前时间,将delTimestamp设置成最大长整型值(Long.MAX_VALUE)。当元素被删除时,我们将delTimestamp更新为当前时间,表示已经被删除。
注意,这里只是标记删除,而非真正将它从容器中删除。
同时,每个迭代器也保存一个迭代器创建时间戳snapshotTimestamp,也就是迭代器对应的快照的创建时间戳。当使用迭代器来遍历容器的时候,只有满足addTimestamp<snapshotTimestamp<delTimestamp的元素,才是属于这个迭代器的快照。
如果元素的addTimestamp>snapshotTimestamp,说明元素在创建了迭代器之后才加入的,不属于这个迭代器的快照;如果元素的delTimestamp<snapshotTimestamp,说明元素在创建迭代器之前就被删除掉了,也不属于这个迭代器的快照。
这样就在不拷贝容器的情况下,在容器本身上借助时间戳实现了快照功能。具体的代码实现如下所示。注意,这里没有考虑ArrayList的扩容问题。
public class ArrayList<E> implements List<E> {
private static final int DEFAULT_CAPACITY = 10;
private int actualSize; //不包含标记删除元素
private int totalSize; //包含标记删除元素
private Object[] elements;
private long[] addTimestamps;
private long[] delTimestamps;
public ArrayList() {
this.elements = new Object[DEFAULT_CAPACITY];
this.addTimestamps = new long[DEFAULT_CAPACITY];
this.delTimestamps = new long[DEFAULT_CAPACITY];
this.totalSize = 0;
this.actualSize = 0;
}
@Override
public void add(E obj) {
elements[totalSize] = obj;
addTimestamps[totalSize] = System.currentTimeMillis();
delTimestamps[totalSize] = Long.MAX_VALUE;
totalSize++;
actualSize++;
}
@Override
public void remove(E obj) {
for (int i = 0; i < totalSize; ++i) {
if (elements[i].equals(obj)) {
delTimestamps[i] = System.currentTimeMillis();
actualSize--;
}
}
}
public int actualSize() {
return this.actualSize;
}
public int totalSize() {
return this.totalSize;
}
public E get(int i) {
if (i >= totalSize) {
throw new IndexOutOfBoundsException();
}
return (E)elements[i];
}
public long getAddTimestamp(int i) {
if (i >= totalSize) {
throw new IndexOutOfBoundsException();
}
return addTimestamps[i];
}
public long getDelTimestamp(int i) {
if (i >= totalSize) {
throw new IndexOutOfBoundsException();
}
return delTimestamps[i];
}
}
public class SnapshotArrayIterator<E> implements Iterator<E> {
private long snapshotTimestamp;
private int cursorInAll; // 在整个容器中的下标,而非快照中的下标
private int leftCount; // 快照中还有几个元素未被遍历
private ArrayList<E> arrayList;
public SnapshotArrayIterator(ArrayList<E> arrayList) {
this.snapshotTimestamp = System.currentTimeMillis();
this.cursorInAll = 0;
this.leftCount = arrayList.actualSize();;
this.arrayList = arrayList;
justNext(); // 先跳到这个迭代器快照的第一个元素
}
@Override
public boolean hasNext() {
return this.leftCount >= 0; // 注意是>=, 而非>
}
@Override
public E next() {
E currentItem = arrayList.get(cursorInAll);
justNext();
return currentItem;
}
private void justNext() {
while (cursorInAll < arrayList.totalSize()) {
long addTimestamp = arrayList.getAddTimestamp(cursorInAll);
long delTimestamp = arrayList.getDelTimestamp(cursorInAll);
if (snapshotTimestamp > addTimestamp && snapshotTimestamp < delTimestamp) {
leftCount--;
break;
}
cursorInAll++;
}
}
}
实际上,上面的解决方案相当于解决了一个问题,又引入了另外一个问题。ArrayList底层依赖数组这种数据结构,原本可以支持快速的随机访问,在O(1)时间复杂度内获取下标为i的元素,但现在,删除数据并非真正的删除,只是通过时间戳来标记删除,这就导致无法支持按照下标快速随机访问了。
解决的方法也不难,可以在ArrayList中存储两个数组。一个支持标记删除的,用来实现快照遍历功能;一个不支持标记删除的(也就是将要删除的数据直接从数组中移除),用来支持随机访问。
访问者模式
访问者模式可以算是23种经典设计模式中最难理解的几个之一。因为它难理解、难实现,应用它会导致代码的可读性、可维护性变差,所以,访问者模式在实际的软件开发中很少被用到,在没有特别必要的情况下,建议不要使用访问者模式。
“发明”访问者模式
假设我们从网站上爬取了很多资源文件,它们的格式有三种:PDF、PPT、Word。我们现在要开发一个工具来处理这批资源文件。这个工具的其中一个功能是,把这些资源文件中的文本内容抽取出来放到txt文件中。
实现这个功能并不难,不同的人有不同的写法。其中,ResourceFile是一个抽象类,包含一个抽象函数extract2txt()。PdfFile、PPTFile、WordFile都继承ResourceFile类,并且重写了extract2txt()函数。在ToolApplication中,可以利用多态特性,根据对象的实际类型,来决定执行哪个方法。
public abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
public abstract void extract2txt();
}
public class PPTFile extends ResourceFile {
public PPTFile(String filePath) {
super(filePath);
}
@Override
public void extract2txt() {
//...省略一大坨从PPT中抽取文本的代码...
//...将抽取出来的文本保存在跟filePath同名的.txt文件中...
System.out.println("Extract PPT.");
}
}
public class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
@Override
public void extract2txt() {
//...
System.out.println("Extract PDF.");
}
}
public class WordFile extends ResourceFile {
public WordFile(String filePath) {
super(filePath);
}
@Override
public void extract2txt() {
//...
System.out.println("Extract WORD.");
}
}
// 运行结果是:
// Extract PDF.
// Extract WORD.
// Extract PPT.
public class ToolApplication {
public static void main(String[] args) {
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
for (ResourceFile resourceFile : resourceFiles) {
resourceFile.extract2txt();
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
如果工具的功能不停地扩展,不仅要能抽取文本内容,还要支持压缩、提取文件元信息(文件名、大小、更新时间等等)构建索引等一系列的功能,那如果我们继续按照上面的实现思路,就会存在这样几个问题:
- 违背开闭原则,添加一个新的功能,所有类的代码都要修改;
- 虽然功能增多,每个类的代码都不断膨胀,可读性和可维护性都变差了;
- 把所有比较上层的业务逻辑都耦合到PdfFile、PPTFile、WordFile类中,导致这些类的职责不够单一,变成了大杂烩。
针对上面的问题,常用的解决方法就是拆分解耦,把业务操作跟具体的数据结构解耦,设计成独立的类。这里按照访问者模式的演进思路来对上面的代码进行重构。重构之后的代码如下所示。
public abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
}
public class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
//...
}
//...PPTFile、WordFile代码省略...
public class Extractor {
public void extract2txt(PPTFile pptFile) {
//...
System.out.println("Extract PPT.");
}
public void extract2txt(PdfFile pdfFile) {
//...
System.out.println("Extract PDF.");
}
public void extract2txt(WordFile wordFile) {
//...
System.out.println("Extract WORD.");
}
}
public class ToolApplication {
public static void main(String[] args) {
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
for (ResourceFile resourceFile : resourceFiles) {
extractor.extract2txt(resourceFile);
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
其中最关键的一点设计是,把抽取文本内容的操作,设计成了三个重载函数。函数重载是Java、C++这类面向对象编程语言中常见的语法机制。所谓重载函数是指,在同一类中函数名相同、参数不同的一组函数。
不过上面的代码是编译通过不了的,第37行会报错。我们知道,多态是一种动态绑定,可以在运行时获取对象的实际类型,来运行实际类型对应的方法。而函数重载是一种静态绑定,在编译时并不能获取对象的实际类型,而是根据声明类型执行声明类型对应的方法。
解决的办法稍微有点难理解,先来看代码。
public abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
abstract public void accept(Extractor extractor);
}
public class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
@Override
public void accept(Extractor extractor) {
extractor.extract2txt(this);
}
//...
}
//...PPTFile、WordFile跟PdfFile类似,这里就省略了...
//...Extractor代码不变...
public class ToolApplication {
public static void main(String[] args) {
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
for (ResourceFile resourceFile : resourceFiles) {
resourceFile.accept(extractor);
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
现在,如果要继续添加新的功能,比如前面提到的压缩功能,根据不同的文件类型,使用不同的压缩算法来压缩资源文件,那么需要实现一个类似Extractor类的新类Compressor类,在其中定义三个重载函数,实现对不同类型资源文件的压缩。除此之外,还要在每个资源文件类中定义新的accept重载函数。
public abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
abstract public void accept(Extractor extractor);
abstract public void accept(Compressor compressor);
}
public class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
@Override
public void accept(Extractor extractor) {
extractor.extract2txt(this);
}
@Override
public void accept(Compressor compressor) {
compressor.compress(this);
}
//...
}
}
//...PPTFile、WordFile跟PdfFile类似,这里就省略了...
//...Extractor代码不变
public class ToolApplication {
public static void main(String[] args) {
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
for (ResourceFile resourceFile : resourceFiles) {
resourceFile.accept(extractor);
}
Compressor compressor = new Compressor();
for(ResourceFile resourceFile : resourceFiles) {
resourceFile.accept(compressor);
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
上面代码还存在一些问题,添加一个新的业务,还是需要修改每个资源文件类,违反了开闭原则。针对这个问题,可以抽象出来一个Visitor接口,包含是三个命名非常通用的visit()重载函数,分别处理三种不同类型的资源文件。具体做什么业务处理,由实现这个Visitor接口的具体的类来决定,比如Extractor负责抽取文本内容,Compressor负责压缩。当我们新添加一个业务功能的时候,资源文件类不需要做任何修改,只需要修改ToolApplication的代码就可以了。
按照这个思路对代码进行重构,重构之后的代码如下所示:
public abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
abstract public void accept(Visitor vistor);
}
public class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
//...
}
//...PPTFile、WordFile跟PdfFile类似,这里就省略了...
public interface Visitor {
void visit(PdfFile pdfFile);
void visit(PPTFile pdfFile);
void visit(WordFile pdfFile);
}
public class Extractor implements Visitor {
@Override
public void visit(PPTFile pptFile) {
//...
System.out.println("Extract PPT.");
}
@Override
public void visit(PdfFile pdfFile) {
//...
System.out.println("Extract PDF.");
}
@Override
public void visit(WordFile wordFile) {
//...
System.out.println("Extract WORD.");
}
}
public class Compressor implements Visitor {
@Override
public void visit(PPTFile pptFile) {
//...
System.out.println("Compress PPT.");
}
@Override
public void visit(PdfFile pdfFile) {
//...
System.out.println("Compress PDF.");
}
@Override
public void visit(WordFile wordFile) {
//...
System.out.println("Compress WORD.");
}
}
public class ToolApplication {
public static void main(String[] args) {
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
for (ResourceFile resourceFile : resourceFiles) {
resourceFile.accept(extractor);
}
Compressor compressor = new Compressor();
for(ResourceFile resourceFile : resourceFiles) {
resourceFile.accept(compressor);
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
重新来看访问者模式
访问者者模式的英文翻译是Visitor Design Pattern。在GoF的《设计模式》一书中,它是这么定义的:
Allows for one or more operation to be applied to a set of objects at runtime, decoupling the operations from the object structure.
翻译成中文就是:允许一个或者多个操作应用到一组对象上,解耦操作和对象本身。
对于访问者模式的代码实现,实际上,在上面例子中,经过层层重构之后的最终代码,就是标准的访问者模式的实现代码。
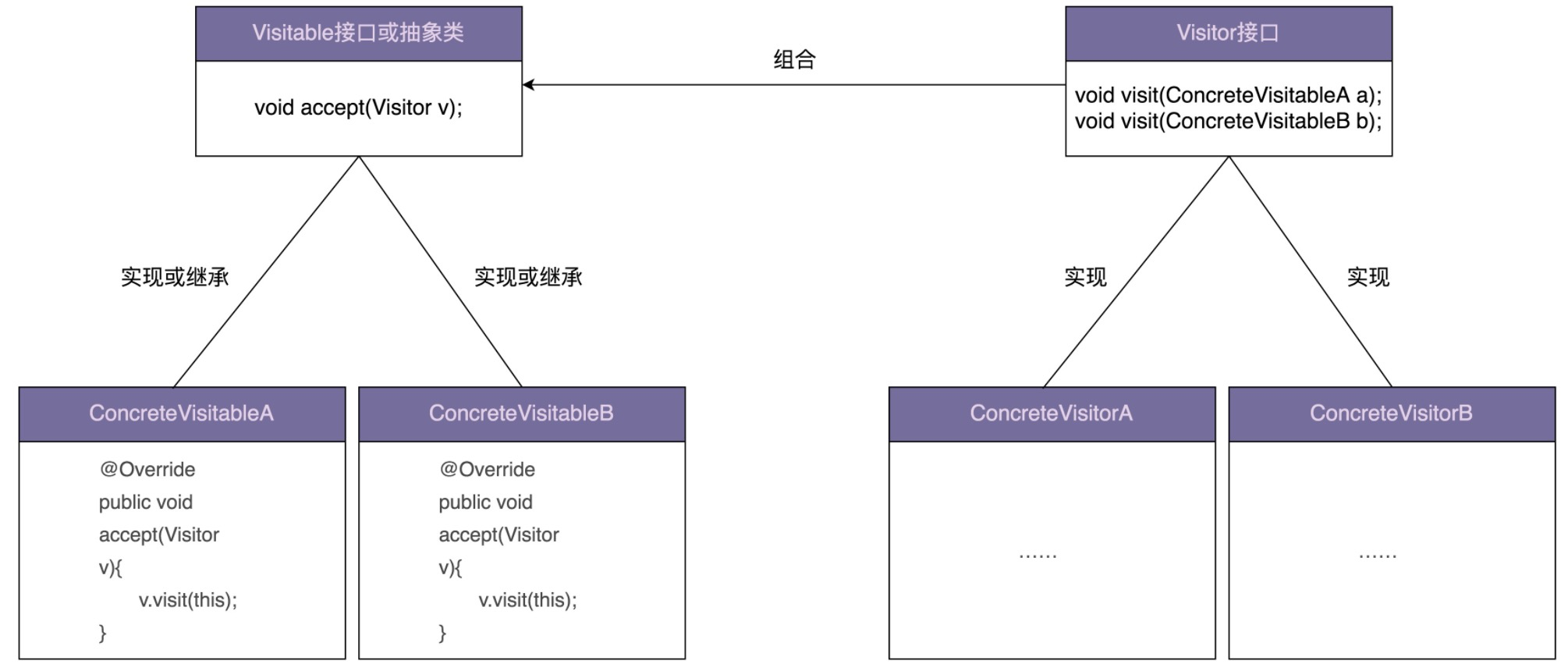
访问者模式的应用场景一般来说,针对的是一组类型不同的对象(PdfFile、PPTFile、WordFile)。不过,尽管这组对象的类型是不同的,但是,它们继承相同的父类(ResourceFile)或者实现相同的接口。在不同的应用场景下,我们需要对这组对象进行一系列不相关的业务操作(抽取文本、压缩等),但为了避免不断添加功能导致类(PdfFile、PPTFile、WordFile)不断膨胀,职责越来越不单一,以及避免频繁地添加功能导致的频繁代码修改,使用访问者模式,将对象与操作解耦,将这些业务操作抽离出来,定义在独立细分的访问者类(Extractor、Compressor)中。
为什么支持双分派的语言不需要访问者模式?
讲到访问者模式,大部分书籍或者资料都会讲到Double Dispatch,中文翻译为双分派。
既然有Double Dispatch,对应的就有Single Dispatch。所谓Single Dispatch,指的是执行哪个对象的方法,根据对象的运行时类型来决定;执行对象的哪个方法,根据方法参数的编译时类型来决定。所谓Double Dispatch,指的是执行哪个对象的方法,根据对象的运行时类型来决定;执行对象的哪个方法,根据方法参数的运行时类型来决定。
如何理解“Dispatch”这个单词呢? 在面向对象编程语言中,我们可以把方法调用理解为一种消息传递,也就是“Dispatch”。一个对象调用另一个对象的方法,就相当于给它发送一条消息。这条消息起码要包含对象名、方法名、方法参数。
如何理解“Single”“Double”这两个单词呢?“Single”“Double”指的是执行哪个对象的哪个方法,跟几个因素的运行时类型有关。我们进一步解释一下。Single Dispatch之所以称为“Single”,是因为执行哪个对象的哪个方法,只跟“对象”的运行时类型有关。Double Dispatch之所以称为“Double”,是因为执行哪个对象的哪个方法,跟“对象”和“方法参数”两者的运行时类型有关。
具体到编程语言的语法机制,Single Dispatch和Double Dispatch跟多态和函数重载直接相关。当前主流的面向对象编程语言(比如,Java、C++、C#)都只支持Single Dispatch,不支持Double Dispatch。
除了访问者模式,其他实现的方案?
开发这个工具有很多种代码设计和实现思路。比如,还可以利用工厂模式来实现,定义一个包含extract2txt()接口函数的Extractor接口。PdfExtractor、PPTExtractor、WordExtractor类实现Extractor接口,并且在各自的extract2txt()函数中,分别实现Pdf、PPT、Word格式文件的文本内容抽取。ExtractorFactory工厂类根据不同的文件类型,返回不同的Extractor。
备忘录模式
备忘录模式的原理与实现
备忘录模式,也叫快照(Snapshot)模式,英文翻译是Memento Design Pattern。在GoF的《设计模式》一书中,备忘录模式是这么定义的:
Captures and externalizes an object’s internal state so that it can be restored later, all without violating encapsulation.
翻译成中文就是:在不违背封装原则的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便之后恢复对象为先前的状态。
假设有这样一道面试题,希望你编写一个小程序,可以接收命令行的输入。用户输入文本时,程序将其追加存储在内存文本中;用户输入“:list”,程序在命令行中输出内存文本的内容;用户输入“:undo”,程序会撤销上一次输入的文本,也就是从内存文本中将上次输入的文本删除掉。
举个例子:
>hello
>:list
hello
>world
>:list
helloworld
>:undo
>:list
hello
整体上来讲,这个小程序实现起来并不复杂。下面一种实现思路:
public class InputText {
private StringBuilder text = new StringBuilder();
public String getText() {
return text.toString();
}
public void append(String input) {
text.append(input);
}
public void setText(String text) {
this.text.replace(0, this.text.length(), text);
}
}
public class SnapshotHolder {
private Stack<InputText> snapshots = new Stack<>();
public InputText popSnapshot() {
return snapshots.pop();
}
public void pushSnapshot(InputText inputText) {
InputText deepClonedInputText = new InputText();
deepClonedInputText.setText(inputText.getText());
snapshots.push(deepClonedInputText);
}
}
public class ApplicationMain {
public static void main(String[] args) {
InputText inputText = new InputText();
SnapshotHolder snapshotsHolder = new SnapshotHolder();
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
String input = scanner.next();
if (input.equals(":list")) {
System.out.println(inputText.getText());
} else if (input.equals(":undo")) {
InputText snapshot = snapshotsHolder.popSnapshot();
inputText.setText(snapshot.getText());
} else {
snapshotsHolder.pushSnapshot(inputText);
inputText.append(input);
}
}
}
}
实际上,备忘录模式的实现很灵活,也没有很固定的实现方式,在不同的业务需求、不同编程语言下,代码实现可能都不大一样。上面的代码基本上已经实现了最基本的备忘录的功能。但是上面的代码并不满足“在不违背封装原则的前提下,进行对象的备份和恢复。”这一点:
- 第一,为了能用快照恢复InputText对象,我们在InputText类中定义了setText()函数,但这个函数有可能会被其他业务使用,所以,暴露不应该暴露的函数违背了封装原则;
- 第二,快照本身是不可变的,理论上讲,不应该包含任何set()等修改内部状态的函数,但在上面的代码实现中,“快照“这个业务模型复用了InputText类的定义,而InputText类本身有一系列修改内部状态的函数,所以,用InputText类来表示快照违背了封装原则。
针对以上问题,对代码做两点修改。其一,定义一个独立的类(Snapshot类)来表示快照,而不是复用InputText类。这个类只暴露get()方法,没有set()等任何修改内部状态的方法。其二,在InputText类中,我们把setText()方法重命名为restoreSnapshot()方法,用意更加明确,只用来恢复对象。
public class InputText {
private StringBuilder text = new StringBuilder();
public String getText() {
return text.toString();
}
public void append(String input) {
text.append(input);
}
public Snapshot createSnapshot() {
return new Snapshot(text.toString());
}
public void restoreSnapshot(Snapshot snapshot) {
this.text.replace(0, this.text.length(), snapshot.getText());
}
}
public class Snapshot {
private String text;
public Snapshot(String text) {
this.text = text;
}
public String getText() {
return this.text;
}
}
public class SnapshotHolder {
private Stack<Snapshot> snapshots = new Stack<>();
public Snapshot popSnapshot() {
return snapshots.pop();
}
public void pushSnapshot(Snapshot snapshot) {
snapshots.push(snapshot);
}
}
public class ApplicationMain {
public static void main(String[] args) {
InputText inputText = new InputText();
SnapshotHolder snapshotsHolder = new SnapshotHolder();
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
String input = scanner.next();
if (input.equals(":list")) {
System.out.println(inputText.toString());
} else if (input.equals(":undo")) {
Snapshot snapshot = snapshotsHolder.popSnapshot();
inputText.restoreSnapshot(snapshot);
} else {
snapshotsHolder.pushSnapshot(inputText.createSnapshot());
inputText.append(input);
}
}
}
}
如何优化内存和时间消耗?
如果要备份的对象数据比较大,备份频率又比较高,那快照占用的内存会比较大,备份和恢复的耗时会比较长。这个问题该如何解决呢?
不同的应用场景下有不同的解决方法。比如前面举的那个例子,应用场景是利用备忘录来实现撤销操作,而且仅仅支持顺序撤销,也就是说,每次操作只能撤销上一次的输入,不能跳过上次输入撤销之前的输入。在具有这样特点的应用场景下,为了节省内存,我们不需要在快照中存储完整的文本,只需要记录少许信息,比如在获取快照当下的文本长度,用这个值结合InputText类对象存储的文本来做撤销操作。
再举一个例子。假设每当有数据改动,我们都需要生成一个备份,以备之后恢复。如果需要备份的数据很大,这样高频率的备份,不管是对存储(内存或者硬盘)的消耗,还是对时间的消耗,都可能是无法接受的。想要解决这个问题,我们一般会采用“低频率全量备份”和“高频率增量备份”相结合的方法。
全量备份就不用讲了,它跟我们上面的例子类似,就是把所有的数据“拍个快照”保存下来。所谓“增量备份”,指的是记录每次操作或数据变动。
当我们需要恢复到某一时间点的备份的时候,如果这一时间点有做全量备份,我们直接拿来恢复就可以了。如果这一时间点没有对应的全量备份,我们就先找到最近的一次全量备份,然后用它来恢复,之后执行此次全量备份跟这一时间点之间的所有增量备份,也就是对应的操作或者数据变动。这样就能减少全量备份的数量和频率,减少对时间、内存的消耗。
命令模式
命令模式Command Design Pattern,在GoF的《设计模式》一书中,它是这么定义的:
The command pattern encapsulates a request as an object, thereby letting us parameterize other objects with different requests, queue or log requests, and support undoable operations.
命令模式将请求(命令)封装为一个对象,这样可以使用不同的请求参数化其他对象(将不同请求依赖注入到其他对象),并且能够支持请求(命令)的排队执行、记录日志、撤销等(附加控制)功能。
对于GoF给出的定义,我这里再进一步解读一下。
落实到编码实现,命令模式用的最核心的实现手段,是将函数封装成对象。我们知道,C语言支持函数指针,可以把函数当作变量传递来传递去。但是,在大部分编程语言中,函数没法儿作为参数传递给其他函数,也没法儿赋值给变量。借助命令模式,我们可以将函数封装成对象。具体来说就是,设计一个包含这个函数的类,实例化一个对象传来传去,这样就可以实现把函数像对象一样使用。从实现的角度来说,它类似之前讲过的回调。
把函数封装成对象之后,对象就可以存储下来,方便控制执行。所以,命令模式的主要作用和应用场景,是用来控制命令的执行,比如,异步、延迟、排队执行命令、撤销重做命令、存储命令、给命令记录日志等等,这才是命令模式能发挥独一无二作用的地方。
命令模式的实战讲解
假设我们正在开发一个类似《天天酷跑》或者《QQ卡丁车》这样的手游。这种游戏本身的复杂度集中在客户端。后端基本上只负责数据(比如积分、生命值、装备)的更新和查询,所以,后端逻辑相对于客户端来说,要简单很多。
为了提高性能,我们会把游戏中玩家的信息保存在内存中。在游戏进行的过程中,只更新内存中的数据,游戏结束之后,再将内存中的数据存档,也就是持久化到数据库中。为了降低实现的难度,一般来说,同一个游戏场景里的玩家,会被分配到同一台服务上。这样,一个玩家拉取同一个游戏场景中的其他玩家的信息,就不需要跨服务器去查找了,实现起来就简单了很多。
一般来说,游戏客户端和服务器之间的数据交互是比较频繁的,所以,为了节省网络连接建立的开销,客户端和服务器之间一般采用长连接的方式来通信。通信的格式有多种,比如Protocol Buffer、JSON、XML,甚至可以自定义格式。不管是什么格式,客户端发送给服务器的请求,一般都包括两部分内容:指令和数据。其中,指令我们也可以叫作事件,数据是执行这个指令所需的数据。
服务器在接收到客户端的请求之后,会解析出指令和数据,并且根据指令的不同,执行不同的处理逻辑。对于这样的一个业务场景,一般有两种架构实现思路。
常用的一种实现思路是利用多线程。一个线程接收请求,接收到请求之后,启动一个新的线程来处理请求。具体点讲,一般是通过一个主线程来接收客户端发来的请求。每当接收到一个请求之后,就从一个专门用来处理请求的线程池中,捞出一个空闲线程来处理。
另一种实现思路是在一个线程内轮询接收请求和处理请求。这种处理方式不太常见。尽管它无法利用多线程多核处理的优势,但是对于IO密集型的业务来说,它避免了多线程不停切换对性能的损耗,并且克服了多线程编程Bug比较难调试的缺点,也算是手游后端服务器开发中比较常见的架构模式了。
接下来就重点讲一下第二种实现方式。
整个手游后端服务器轮询获取客户端发来的请求,获取到请求之后,借助命令模式,把请求包含的数据和处理逻辑封装为命令对象,并存储在内存队列中。然后,再从队列中取出一定数量的命令来执行。执行完成之后,再重新开始新的一轮轮询。具体的示例代码如下所示:
public interface Command {
void execute();
}
public class GotDiamondCommand implements Command {
// 省略成员变量
public GotDiamondCommand(/*数据*/) {
//...
}
@Override
public void execute() {
// 执行相应的逻辑
}
}
//GotStartCommand/HitObstacleCommand/ArchiveCommand类省略
public class GameApplication {
private static final int MAX_HANDLED_REQ_COUNT_PER_LOOP = 100;
private Queue<Command> queue = new LinkedList<>();
public void mainloop() {
while (true) {
List<Request> requests = new ArrayList<>();
//省略从epoll或者select中获取数据,并封装成Request的逻辑,
//注意设置超时时间,如果很长时间没有接收到请求,就继续下面的逻辑处理。
for (Request request : requests) {
Event event = request.getEvent();
Command command = null;
if (event.equals(Event.GOT_DIAMOND)) {
command = new GotDiamondCommand(/*数据*/);
} else if (event.equals(Event.GOT_STAR)) {
command = new GotStartCommand(/*数据*/);
} else if (event.equals(Event.HIT_OBSTACLE)) {
command = new HitObstacleCommand(/*数据*/);
} else if (event.equals(Event.ARCHIVE)) {
command = new ArchiveCommand(/*数据*/);
} // ...一堆else if...
queue.add(command);
}
int handledCount = 0;
while (handledCount < MAX_HANDLED_REQ_COUNT_PER_LOOP) {
if (queue.isEmpty()) {
break;
}
Command command = queue.poll();
command.execute();
}
}
}
}
命令模式 VS 策略模式
你可能会觉得,命令模式跟策略模式、工厂模式非常相似啊,那它们的区别在哪里呢?
实际上,每个设计模式都应该由两部分组成:第一部分是应用场景,即这个模式可以解决哪类问题;第二部分是解决方案,即这个模式的设计思路和具体的代码实现。不过,代码实现并不是模式必须包含的。如果你单纯地只关注解决方案这一部分,甚至只关注代码实现,就会产生大部分模式看起来都很相似的错觉。
实际上,设计模式之间的主要区别还是在于设计意图,也就是应用场景。单纯地看设计思路或者代码实现,有些模式确实很相似,比如策略模式和工厂模式。
之前讲策略模式的时候,我们有讲到,策略模式包含策略的定义、创建和使用三部分,从代码结构上来,它非常像工厂模式。它们的区别在于,策略模式侧重“策略”或“算法”这个特定的应用场景,用来解决根据运行时状态从一组策略中选择不同策略的问题,而工厂模式侧重封装对象的创建过程,这里的对象没有任何业务场景的限定,可以是策略,但也可以是其他东西。从设计意图上来,这两个模式完全是两回事儿。
有了刚刚的铺垫,接下来,我们再来看命令模式跟策略模式的区别。你可能会觉得,命令的执行逻辑也可以看作策略,那它是不是就是策略模式了呢?实际上,这两者有一点细微的区别。
在策略模式中,不同的策略具有相同的目的、不同的实现、互相之间可以替换。比如,BubbleSort、SelectionSort都是为了实现排序的,只不过一个是用冒泡排序算法来实现的,另一个是用选择排序算法来实现的。而在命令模式中,不同的命令具有不同的目的,对应不同的处理逻辑,并且互相之间不可替换。
解释器模式
解释器模式的原理和实现
解释器模式Interpreter Design Pattern,在GoF的《设计模式》一书中,它是这样定义的:
Interpreter pattern is used to defines a grammatical representation for a language and provides an interpreter to deal with this grammar.
翻译成中文就是:解释器模式为某个语言定义它的语法(或者叫文法)表示,并定义一个解释器用来处理这个语法。
假设一个新的加减乘除计算“语言”,语法规则如下:
- 运算符只包含加、减、乘、除,并且没有优先级的概念;
- 表达式(也就是前面提到的“句子”)中,先书写数字,后书写运算符,空格隔开;
- 按照先后顺序,取出两个数字和一个运算符计算结果,结果重新放入数字的最头部位置,循环上述过程,直到只剩下一个数字,这个数字就是表达式最终的计算结果。
比如“ 8 3 2 4 - + * ”这样一个表达式,按照上面的语法规则来处理,取出数字“8 3”和“-”运算符,计算得到5,于是表达式就变成了“ 5 2 4 + * ”。然后,再取出“ 5 2 ”和“ + ”运算符,计算得到7,表达式就变成了“ 7 4 * ”。最后,取出“ 7 4”和“ * ”运算符,最终得到的结果就是28。
用代码实现出来如下所示。
public class ExpressionInterpreter {
private Deque<Long> numbers = new LinkedList<>();
public long interpret(String expression) {
String[] elements = expression.split(" ");
int length = elements.length;
for (int i = 0; i < (length+1)/2; ++i) {
numbers.addLast(Long.parseLong(elements[i]));
}
for (int i = (length+1)/2; i < length; ++i) {
String operator = elements[i];
boolean isValid = "+".equals(operator) || "-".equals(operator)
|| "*".equals(operator) || "/".equals(operator);
if (!isValid) {
throw new RuntimeException("Expression is invalid: " + expression);
}
long number1 = numbers.pollFirst();
long number2 = numbers.pollFirst();
long result = 0;
if (operator.equals("+")) {
result = number1 + number2;
} else if (operator.equals("-")) {
result = number1 - number2;
} else if (operator.equals("*")) {
result = number1 * number2;
} else if (operator.equals("/")) {
result = number1 / number2;
}
numbers.addFirst(result);
}
if (numbers.size() != 1) {
throw new RuntimeException("Expression is invalid: " + expression);
}
return numbers.pop();
}
}
在上面的代码实现中,语法规则的解析逻辑(第23、25、27、29行)都集中在一个函数中,对于简单的语法规则的解析,这样的设计就足够了。但是,对于复杂的语法规则的解析,逻辑复杂,代码量多,所有的解析逻辑都耦合在一个函数中,这样显然是不合适的。这个时候,就要考虑拆分代码,将解析逻辑拆分到独立的小类中。
解释器模式的代码实现比较灵活,没有固定的模板。
它的代码实现的核心思想,就是将语法解析的工作拆分到各个小类中,以此来避免大而全的解析类。一般的做法是,将语法规则拆分成一些小的独立的单元,然后对每个单元进行解析,最终合并为对整个语法规则的解析。
前面定义的语法规则有两类表达式,一类是数字,一类是运算符,运算符又包括加减乘除。利用解释器模式,我们把解析的工作拆分到NumberExpression、AdditionExpression、SubstractionExpression、MultiplicationExpression、DivisionExpression这样五个解析类中。
按照这个思路重构之后的代码如下所示。
public interface Expression {
long interpret();
}
public class NumberExpression implements Expression {
private long number;
public NumberExpression(long number) {
this.number = number;
}
public NumberExpression(String number) {
this.number = Long.parseLong(number);
}
@Override
public long interpret() {
return this.number;
}
}
public class AdditionExpression implements Expression {
private Expression exp1;
private Expression exp2;
public AdditionExpression(Expression exp1, Expression exp2) {
this.exp1 = exp1;
this.exp2 = exp2;
}
@Override
public long interpret() {
return exp1.interpret() + exp2.interpret();
}
}
// SubstractionExpression/MultiplicationExpression/DivisionExpression与AdditionExpression代码结构类似,这里就省略了
public class ExpressionInterpreter {
private Deque<Expression> numbers = new LinkedList<>();
public long interpret(String expression) {
String[] elements = expression.split(" ");
int length = elements.length;
for (int i = 0; i < (length+1)/2; ++i) {
numbers.addLast(new NumberExpression(elements[i]));
}
for (int i = (length+1)/2; i < length; ++i) {
String operator = elements[i];
boolean isValid = "+".equals(operator) || "-".equals(operator)
|| "*".equals(operator) || "/".equals(operator);
if (!isValid) {
throw new RuntimeException("Expression is invalid: " + expression);
}
Expression exp1 = numbers.pollFirst();
Expression exp2 = numbers.pollFirst();
Expression combinedExp = null;
if (operator.equals("+")) {
combinedExp = new AdditionExpression(exp1, exp2);
} else if (operator.equals("-")) {
combinedExp = new AdditionExpression(exp1, exp2);
} else if (operator.equals("*")) {
combinedExp = new AdditionExpression(exp1, exp2);
} else if (operator.equals("/")) {
combinedExp = new AdditionExpression(exp1, exp2);
}
long result = combinedExp.interpret();
numbers.addFirst(new NumberExpression(result));
}
if (numbers.size() != 1) {
throw new RuntimeException("Expression is invalid: " + expression);
}
return numbers.pop().interpret();
}
}
解释器模式实战举例
在我们平时的项目开发中,监控系统非常重要,它可以时刻监控业务系统的运行情况,及时将异常报告给开发者。比如,如果每分钟接口出错数超过100,监控系统就通过短信、微信、邮件等方式发送告警给开发者。
一般来讲,监控系统支持开发者自定义告警规则,比如我们可以用下面这样一个表达式,来表示一个告警规则,它表达的意思是:每分钟API总出错数超过100或者每分钟API总调用数超过10000就触发告警。
api_error_per_minute > 100 || api_count_per_minute > 10000
在监控系统中,告警模块只负责根据统计数据和告警规则,判断是否触发告警。至于每分钟API接口出错数、每分钟接口调用数等统计数据的计算,是由其他模块来负责的。其他模块将统计数据放到一个Map中(数据的格式如下所示),发送给告警模块。接下来,我们只关注告警模块。
Map<String, Long> apiStat = new HashMap<>();
apiStat.put("api_error_per_minute", 103);
apiStat.put("api_count_per_minute", 987);
为了简化讲解和代码实现,我们假设自定义的告警规则只包含“||、&&、>、<、==”这五个运算符,其中,“>、<、==”运算符的优先级高于“||、&&”运算符,“&&”运算符优先级高于“||”。在表达式中,任意元素之间需要通过空格来分隔。除此之外,用户可以自定义要监控的key,比如前面的api_error_per_minute、api_count_per_minute。
public class AlertRuleInterpreter {
// key1 > 100 && key2 < 1000 || key3 == 200
public AlertRuleInterpreter(String ruleExpression) {
//TODO:由你来完善
}
//<String, Long> apiStat = new HashMap<>();
//apiStat.put("key1", 103);
//apiStat.put("key2", 987);
public boolean interpret(Map<String, Long> stats) {
//TODO:由你来完善
}
}
public class DemoTest {
public static void main(String[] args) {
String rule = "key1 > 100 && key2 < 30 || key3 < 100 || key4 == 88";
AlertRuleInterpreter interpreter = new AlertRuleInterpreter(rule);
Map<String, Long> stats = new HashMap<>();
stats.put("key1", 101l);
stats.put("key3", 121l);
stats.put("key4", 88l);
boolean alert = interpreter.interpret(stats);
System.out.println(alert);
}
}
实际上,我们可以把自定义的告警规则,看作一种特殊“语言”的语法规则。实现一个解释器,能够根据规则,针对用户输入的数据,判断是否触发告警。利用解释器模式,可以把解析表达式的逻辑拆分到各个小类中,避免大而复杂的大类的出现。
public interface Expression {
boolean interpret(Map<String, Long> stats);
}
public class GreaterExpression implements Expression {
private String key;
private long value;
public GreaterExpression(String strExpression) {
String[] elements = strExpression.trim().split("\\s+");
if (elements.length != 3 || !elements[1].trim().equals(">")) {
throw new RuntimeException("Expression is invalid: " + strExpression);
}
this.key = elements[0].trim();
this.value = Long.parseLong(elements[2].trim());
}
public GreaterExpression(String key, long value) {
this.key = key;
this.value = value;
}
@Override
public boolean interpret(Map<String, Long> stats) {
if (!stats.containsKey(key)) {
return false;
}
long statValue = stats.get(key);
return statValue > value;
}
}
// LessExpression/EqualExpression跟GreaterExpression代码类似,这里就省略了
public class AndExpression implements Expression {
private List<Expression> expressions = new ArrayList<>();
public AndExpression(String strAndExpression) {
String[] strExpressions = strAndExpression.split("&&");
for (String strExpr : strExpressions) {
if (strExpr.contains(">")) {
expressions.add(new GreaterExpression(strExpr));
} else if (strExpr.contains("<")) {
expressions.add(new LessExpression(strExpr));
} else if (strExpr.contains("==")) {
expressions.add(new EqualExpression(strExpr));
} else {
throw new RuntimeException("Expression is invalid: " + strAndExpression);
}
}
}
public AndExpression(List<Expression> expressions) {
this.expressions.addAll(expressions);
}
@Override
public boolean interpret(Map<String, Long> stats) {
for (Expression expr : expressions) {
if (!expr.interpret(stats)) {
return false;
}
}
return true;
}
}
public class OrExpression implements Expression {
private List<Expression> expressions = new ArrayList<>();
public OrExpression(String strOrExpression) {
String[] andExpressions = strOrExpression.split("\\|\\|");
for (String andExpr : andExpressions) {
expressions.add(new AndExpression(andExpr));
}
}
public OrExpression(List<Expression> expressions) {
this.expressions.addAll(expressions);
}
@Override
public boolean interpret(Map<String, Long> stats) {
for (Expression expr : expressions) {
if (expr.interpret(stats)) {
return true;
}
}
return false;
}
}
public class AlertRuleInterpreter {
private Expression expression;
public AlertRuleInterpreter(String ruleExpression) {
this.expression = new OrExpression(ruleExpression);
}
public boolean interpret(Map<String, Long> stats) {
return expression.interpret(stats);
}
}
中介模式
中介模式的原理和实现
中介模式Mediator Design Pattern,在GoF中的《设计模式》一书中,它是这样定义的:
Mediator pattern defines a separate (mediator) object that encapsulates the interaction between a set of objects and the objects delegate their interaction to a mediator object instead of interacting with each other directly.
翻译成中文就是:中介模式定义了一个单独的(中介)对象,来封装一组对象之间的交互。将这组对象之间的交互委派给与中介对象交互,来避免对象之间的直接交互。
实际上,中介模式的设计思想跟中间层很像,通过引入中介这个中间层,将一组对象之间的交互关系(或者说依赖关系)从多对多(网状关系)转换为一对多(星状关系)。原来一个对象要跟n个对象交互,现在只需要跟一个中介对象交互,从而最小化对象之间的交互关系,降低了代码的复杂度,提高了代码的可读性和可维护性。
提到中介模式,有一个比较经典的例子不得不说,那就是航空管制。
为了让飞机在飞行的时候互不干扰,每架飞机都需要知道其他飞机每时每刻的位置,这就需要时刻跟其他飞机通信。飞机通信形成的通信网络就会无比复杂。这个时候,我们通过引入“塔台”这样一个中介,让每架飞机只跟塔台来通信,发送自己的位置给塔台,由塔台来负责每架飞机的航线调度。这样就大大简化了通信网络。
刚刚举的是生活中的例子,再举一个跟编程开发相关的例子。这个例子与UI控件有关,算是中介模式比较经典的应用,很多书籍在讲到中介模式的时候,都会拿它来举例。
假设有一个比较复杂的对话框,对话框中有很多控件,比如按钮、文本框、下拉框等。当对某个控件进行操作的时候,其他控件会做出相应的反应,比如,在下拉框中选择“注册”,注册相关的控件就会显示在对话框中。如果在下拉框中选择“登陆”,登陆相关的控件就会显示在对话框中。
按照通常我们习惯的UI界面的开发方式,将刚刚的需求用代码实现出来,就是下面这个样子。在这种实现方式中,控件和控件之间互相操作、互相依赖。
public class UIControl {
private static final String LOGIN_BTN_ID = "login_btn";
private static final String REG_BTN_ID = "reg_btn";
private static final String USERNAME_INPUT_ID = "username_input";
private static final String PASSWORD_INPUT_ID = "pswd_input";
private static final String REPEATED_PASSWORD_INPUT_ID = "repeated_pswd_input";
private static final String HINT_TEXT_ID = "hint_text";
private static final String SELECTION_ID = "selection";
public static void main(String[] args) {
Button loginButton = (Button)findViewById(LOGIN_BTN_ID);
Button regButton = (Button)findViewById(REG_BTN_ID);
Input usernameInput = (Input)findViewById(USERNAME_INPUT_ID);
Input passwordInput = (Input)findViewById(PASSWORD_INPUT_ID);
Input repeatedPswdInput = (Input)findViewById(REPEATED_PASSWORD_INPUT_ID);
Text hintText = (Text)findViewById(HINT_TEXT_ID);
Selection selection = (Selection)findViewById(SELECTION_ID);
loginButton.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
String username = usernameInput.text();
String password = passwordInput.text();
//校验数据...
//做业务处理...
}
});
regButton.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
//获取usernameInput、passwordInput、repeatedPswdInput数据...
//校验数据...
//做业务处理...
}
});
//...省略selection下拉选择框相关代码....
}
}
再按照中介模式,将上面的代码重新实现一下。在新的代码实现中,各个控件只跟中介对象交互,中介对象负责所有业务逻辑的处理。
public interface Mediator {
void handleEvent(Component component, String event);
}
public class LandingPageDialog implements Mediator {
private Button loginButton;
private Button regButton;
private Selection selection;
private Input usernameInput;
private Input passwordInput;
private Input repeatedPswdInput;
private Text hintText;
@Override
public void handleEvent(Component component, String event) {
if (component.equals(loginButton)) {
String username = usernameInput.text();
String password = passwordInput.text();
//校验数据...
//做业务处理...
} else if (component.equals(regButton)) {
//获取usernameInput、passwordInput、repeatedPswdInput数据...
//校验数据...
//做业务处理...
} else if (component.equals(selection)) {
String selectedItem = selection.select();
if (selectedItem.equals("login")) {
usernameInput.show();
passwordInput.show();
repeatedPswdInput.hide();
hintText.hide();
//...省略其他代码
} else if (selectedItem.equals("register")) {
//....
}
}
}
}
public class UIControl {
private static final String LOGIN_BTN_ID = "login_btn";
private static final String REG_BTN_ID = "reg_btn";
private static final String USERNAME_INPUT_ID = "username_input";
private static final String PASSWORD_INPUT_ID = "pswd_input";
private static final String REPEATED_PASSWORD_INPUT_ID = "repeated_pswd_input";
private static final String HINT_TEXT_ID = "hint_text";
private static final String SELECTION_ID = "selection";
public static void main(String[] args) {
Button loginButton = (Button)findViewById(LOGIN_BTN_ID);
Button regButton = (Button)findViewById(REG_BTN_ID);
Input usernameInput = (Input)findViewById(USERNAME_INPUT_ID);
Input passwordInput = (Input)findViewById(PASSWORD_INPUT_ID);
Input repeatedPswdInput = (Input)findViewById(REPEATED_PASSWORD_INPUT_ID);
Text hintText = (Text)findViewById(HINT_TEXT_ID);
Selection selection = (Selection)findViewById(SELECTION_ID);
Mediator dialog = new LandingPageDialog();
dialog.setLoginButton(loginButton);
dialog.setRegButton(regButton);
dialog.setUsernameInput(usernameInput);
dialog.setPasswordInput(passwordInput);
dialog.setRepeatedPswdInput(repeatedPswdInput);
dialog.setHintText(hintText);
dialog.setSelection(selection);
loginButton.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
dialog.handleEvent(loginButton, "click");
}
});
regButton.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
dialog.handleEvent(regButton, "click");
}
});
//....
}
}
从代码中我们可以看出,原本业务逻辑会分散在各个控件中,现在都集中到了中介类中。实际上,这样做既有好处,也有坏处。好处是简化了控件之间的交互,坏处是中介类有可能会变成大而复杂的“上帝类”(God Class)。所以,在使用中介模式的时候,我们要根据实际的情况,平衡对象之间交互的复杂度和中介类本身的复杂度。
中介模式 VS 观察者模式
前面讲观察者模式的时候讲到,观察者模式有多种实现方式。虽然经典的实现方式没法彻底解耦观察者和被观察者,观察者需要注册到被观察者中,被观察者状态更新需要调用观察者的update()方法。但是,在跨进程的实现方式中,可以利用消息队列实现彻底解耦,观察者和被观察者都只需要跟消息队列交互,观察者完全不知道被观察者的存在,被观察者也完全不知道观察者的存在。
前面提到,中介模式也是为了解耦对象之间的交互,所有的参与者都只与中介进行交互。而观察者模式中的消息队列,就有点类似中介模式中的“中介”,观察者模式的中观察者和被观察者,就有点类似中介模式中的“参与者”。那问题来了:中介模式和观察者模式的区别在哪里呢?什么时候选择使用中介模式?什么时候选择使用观察者模式呢?
在观察者模式中,尽管一个参与者既可以是观察者,同时也可以是被观察者,但是,大部分情况下,交互关系往往都是单向的,一个参与者要么是观察者,要么是被观察者,不会兼具两种身份。也就是说,在观察者模式的应用场景中,参与者之间的交互关系比较有条理。
而中介模式正好相反。只有当参与者之间的交互关系错综复杂,维护成本很高的时候,我们才考虑使用中介模式。毕竟,中介模式的应用会带来一定的副作用,前面也讲到,它有可能会产生大而复杂的上帝类。除此之外,如果一个参与者状态的改变,其他参与者执行的操作有一定先后顺序的要求,这个时候,中介模式就可以利用中介类,通过先后调用不同参与者的方法,来实现顺序的控制,而观察者模式是无法实现这样的顺序要求的。